Set
- Set 接口是Collection 的子接口, set 接口没有提供额外的方法
- Set 集合不允许包含相同的元素,如果试把两个相同的元素加入同一个Set 集合中,则添加操作失败。
- Set 判断两个对象是否相同不是使用 == 运算符,而是根据 equals() 方法
特性解读:
- 无序性:不等于随机性。存储的数据在底层数组中并非按照数组索引的顺序添加,而是根据数据的哈希值决定的
- 不可重复性:保证添加的元素按照equals()判断时,不能返回true.即:相同的元素只能添加一个
添加数据:向Set(主要指:HashSet、LinkedHashSet)中添加的数据,其所在的类一定要重写hashCode()和equals()
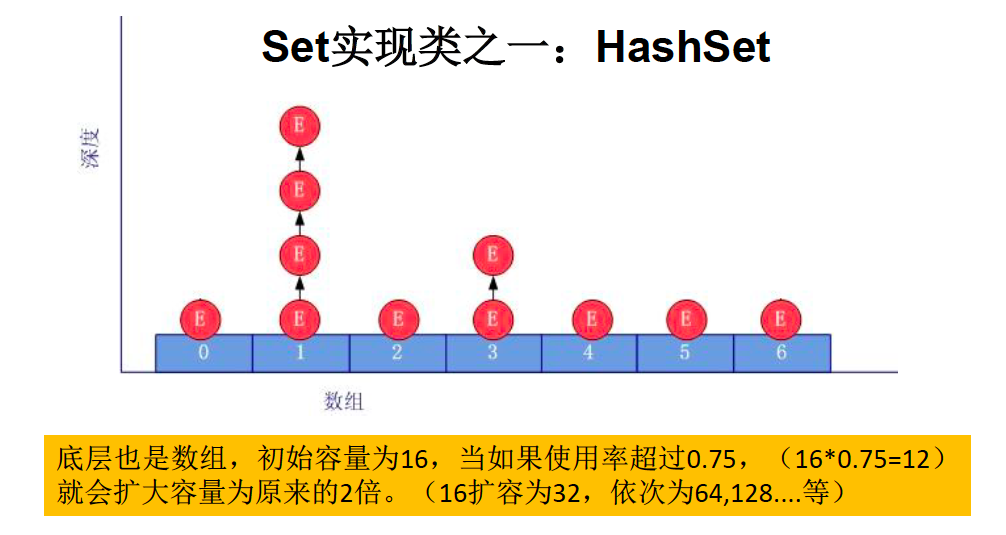
HashSet
- 数组+链表的结构,Set接口的主要实现类,线程不安全,可以存储null值
添加过程,以HashSet为例,添加元素a:
- 首先调用hashCode(),计算hash值,以此hash值通过底层算法计算出在HashSet底层数组中的存放位置(索引位置)
- 如果此位置没有元素,a添加成功; 如果此位置有其他元素b, 则比较a和b的hash值
- 如果hash值不相同, a添加成功; 如果hash值相同,则调用equals方法
- equals为true, 则a添加失败; 反之
LinkedHashSet extends HashSet
HashSet的子类,遍历内部数据时,可以按照添加的顺序遍历
- LinkedHashSet 根据元素的 hashCode 值来决定元素的存储位置,但它同时使用双向链表维护元素的次序这使得元素看起来是以插入顺序保存的。
- LinkedHashSet 插入性能略低于 HashSet 但在迭代访问 Set 里的全
TreeSet
可以按照添加对象的指定属性,进行排序
向TreeSet中添加的数据,要求是相同类的对象
自然排序
比较两个对象是否相同的标准为:compareTo()返回0.不再是equals()
- BigDecimal 、 BigInteger 以及所有的数值型对应的包装类:按它们对应的数值大小进行比较
- Character :按字符的 unicode 值来进行比较
- Boolean true 对应的包装类实例大于 false 对应的包装类实例
- String :按字符串中字符的 unicode 值进行比较
- Date 、 Time :后边的时间、日期比前面的时间、日期大
//自然排序
@Test
public void t2(){
TreeSet set = new TreeSet();
set.add(new User("Tom",12));
set.add(new User("Jerry",32));
set.add(new User("Jim",2));
set.add(new User("Mike",65));
set.add(new User("Jack",33));
set.add(new User("Jack",56));
Iterator iterator = set.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
}
//user
package collection.collection;
public class User implements Comparable{
private String name;
private int age;
public User() {
}
public User(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "User{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public boolean equals(Object o) {
System.out.println("User equals()....");
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
User user = (User) o;
if (age != user.age) return false;
return name != null ? name.equals(user.name) : user.name == null;
}
@Override
public int hashCode() { //return name.hashCode() + age;
int result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
return result;
}
//按照姓名从大到小排列,年龄从小到大排列
@Override
public int compareTo(Object o) {
System.out.println("User compareTo");
if(o instanceof User){
User user = (User)o;
// return -this.name.compareTo(user.name);
int compare = -this.name.compareTo(user.name);
if(compare != 0){
return compare;
}else{
return Integer.compare(this.age,user.age);
}
}else{
throw new RuntimeException("输入的类型不匹配");
}
}
}
定制排序
比较两个对象是否相同的标准为:compare()返回0.不再是equals()
//定制排序
@Test
public void t3(){
Comparator com = new Comparator() {
//按照年龄从小到大排列
@Override
public int compare(Object o1, Object o2) {
if(o1 instanceof User && o2 instanceof User){
User u1 = (User)o1;
User u2 = (User)o2;
return Integer.compare(u1.getAge(),u2.getAge());
}else{
throw new RuntimeException("输入的数据类型不匹配");
}
}
};
TreeSet set = new TreeSet(com);
set.add(new User("Tom",12));
set.add(new User("Jerry",32));
set.add(new User("Jim",2));
set.add(new User("Mike",65));
set.add(new User("Mary",33));
set.add(new User("Jack",33));
set.add(new User("Jack",56));
Iterator iterator = set.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
}
IDEA 复写 hashCode 方法,为什么有 31 这个数字?
- 选择系数的时候要选择尽量大的系数。因为如果计算出来的 hash 地址越大,所谓的“冲突”就越少,查找起来效率也会提高。(减少冲突)
- 并且 31 只占用 5bits, 相乘造成数据溢出的概率较小。
- 31 可以 由 i*31== (i<<5) 1 来表示 现在很多虚拟机里面都有做相关优化。提高算法效率)
- 31 是一个素数,素数作用就是如果我用一个数字来乘以这个素数,那么最终出来的结果只能被素数本身和被乘数还有 1 来整除减少冲突
常见题
//去重
@Test
public void t4(){
List list = new ArrayList();
list.add(new Integer(1));
list.add(new Integer(2));
list.add(new Integer(2));
list.add(new Integer(4));
list.add(new Integer(4));
List list2 = duplicateList(list);
for (Object integer : list2) {
System.out.println(integer);
}
}
public static List duplicateList(List list) {
HashSet set = new HashSet();
set.addAll(list);
return new ArrayList(set);
}
@Test
public void test5(){
HashSet set = new HashSet();
User u1 = new User("Tom",12);
User u2 = new User("Jack",15);
set.add(u1);
set.add(u2);
System.out.println(set);
u1.setName("cc");
set.remove(u1);//会失败,add时是以Tom为hash值对应的位置,以cc得到的hash值不在以Tom为hash值的位置
System.out.println(set);
set.add(new User("cc",12));//新位置
System.out.println(set);
set.add(new User("Tom",12));//也能加成功,hashCode值一样,但equals的时候不一样,因为u1变为cc了
System.out.println(set);
}