Spring WebFlux核心原理
示例代码:https://gitee.com/ixinglan/spring-webflux-demo.git
一、Project Reactor介绍
1.1 Spring WebFlux 与Project Reactor
Spring Framework从版本5开始,基于Project Reactor支持响应式编程。
Project Reactor是用于在JVM上构建非阻塞应用程序的Reactive库,基于Reactive Streams规范。
Project Reactor是Spring生态系统中响应式的基础,并且与Spring密切合作进行开发。
Spring WebFlux要求Project Reactor作为核心依赖项。
模块
Project Reactor由Reactor文档中列出的一组模块组成。
主要组件是Reactor Core,其中包含响应式类型Flux和Mono,它们实现了Reactive Stream的Publisher接口以及一组可应用于这些类型的运算符。
其他一些模块是:
Reactor Test ——提供一些实用程序来测试响应流。
Reactor Extra ——提供一些额外的Flux运算符。
Reactor Netty ——无阻塞且支持背压的TCP,HTTP和UDP的客户端和服务器。
Reactor Adapter ——用于与其他响应式库(例如RxJava2和Akka Streams)的适配。
Reactor Kafka ——用于Kafka的响应式API,作为Kafka的生产者和消费者
并发模型
有两种在响应式链中切换执行的方式: publishOn 和 subscribeOn
publishOn(Scheduler scheduler) ——影响所有后续运算符的执行(只要未指定其他任何内容)
subscribeOn(Scheduler scheduler) ——根据链中最早的subscribeOn调用,更改整个操作符链所订阅的线程。它不影响随后对publishOn的调用的行为。
Schedulers类包含用于提供执行上下文的静态方法:
parallel() ——为并行工作而调整的固定工作池,可创建与CPU内核数量一样多的工作线程池。
single() ——单个可重用线程。此方法为所有调用方重用同一线程,直到调度程序被释放为止。如果您希望使用按呼叫专用线 程,则可以为每个呼叫使用Schedulers.newSingle()。
boundedElastic() ——动态创建一定数量的工作者。它限制了它可以创建的支持线程的数量,并且可以在线程可用时重新调度要排队的任务。这是包装同步阻塞调用的不错选择。
immediate() ——立即在执行线程上运行,而不切换执行上下文。
fromExecutorService(ExecutorService) ——可用于从任何现有ExecutorService中创建调度程序。
1.2 Project Reactor 1.x版本
public static void main(String[] args) {
// 创建Environment实例。
// Environment实例是执行上下文,负责创建特定的Dispatcher。
// 可以提供不同类型的分派程序,范围包括进程间分派到分布式分派。
Environment env = new Environment();
/*
创建Reactor实例,它是Reactor模式的直接实现。
我们使用Reactors类创建Reactor实例。
使用基于RingBuffer结构的Dispatcher预定义实现。
*/
Reactor reactor = Reactors.reactor()
.env(env)
.dispatcher(Environment.RING_BUFFER)
.get();
// 声明通道Selector和Event消费者声明。注册一个事件处理程序:打印
// 通过字符串选择器进行过滤,该字符串选择器指示事件通道的名称。
// Selectors.$提供了更全面的标准选择,因此事件选择的最终表达式可能更复杂。
reactor.on($("channel"), event -> System.out.println(event.getData()));
/*
底层实现中,事件由Dispatcher进行处理,然后发送到目的地。
根据Dispatcher的实现,可以同步或异步处理事件。
这提供了一种功能分解,并且通常以与Spring框架事件处理方法类似的方式工作。
*/
Executors.newSingleThreadScheduledExecutor().scheduleAtFixedRate(() -> {
// 给通道发送通知
reactor.notify("channel", Event.wrap("test"));
}, 0, 100, TimeUnit.MICROSECONDS);
}
public static void main(String[] args) {
Environment env = new Environment();
/*
Reactor实例是一个事件网关,允许其他组件注册事件消费者,这些事件消费者随后会得到事件
的通知。
消费者一般通过Selector进行注册,通过匹配通知的key,消费事件。
Reactor得到事件通知时,Reactor通过Dispatcher分发任务
任务在线程中执行。
根据Dispatcher实现的不同,线程的调度不同。
*/
Reactor reactor = Reactors.reactor(env);
// on方法使用指定的Selector将Stream关联到Observable
Stream<String> stream = Streams.on(reactor, $("channel"));
stream.map(s->"hello lagou - " + s)
.distinct() // 对连续的相同值进行去重
.filter((Predicate<String>) s -> s.length() > 2)
.consume(System.out::println);
// 使用指定的环境创建一个延迟流
// 第一个泛型表示值类型
// 第二个泛型表示可以消费值的消费者类型
Deferred<String, Stream<String>> input = Streams.defer(env);
// 获取Composable的子类,用于消费异常和值
Stream<String> compose = input.compose();
compose.map(m -> m + " = hello lagou")
.filter((Function<String, Boolean>) s -> s.contains("123"))
.map(Event::wrap) // 将数据封装为事件
// reactor.prepare方法用于创建一个优化的路径,给指定的key广播事件通知
.consume(reactor.prepare("channel")); // 给当前Composable关联一个消费者,消费composable的数据
for (int i = 0; i < 1000; i++) {
// 接收指定的值,让底层的Composable可以消费
input.accept(UUID.randomUUID().toString());
}
}
通过与Spring框架的完美集成以及与Netty的组合,非常适合开发具备异步和非阻塞消息处理的高性能系统。
Reactor 1.x的缺点:
该库没有背压控制。
除了阻塞生产线程或跳过事件之外,事件驱动的Reactor 1.x并没有提供控制背压的方法。
错误处理非常复杂
Reactor 1.x提供了几种处理错误和失败的方法,但是使用比较复杂。
1.3 Project Reactor 2.x版本
Stephane Maldini和Jon Brisbin在2015年初宣布Reactor 2.x版本。
Stephane Maldini形容Reactor 2.x:Reactor 2首开响应式流的先河。
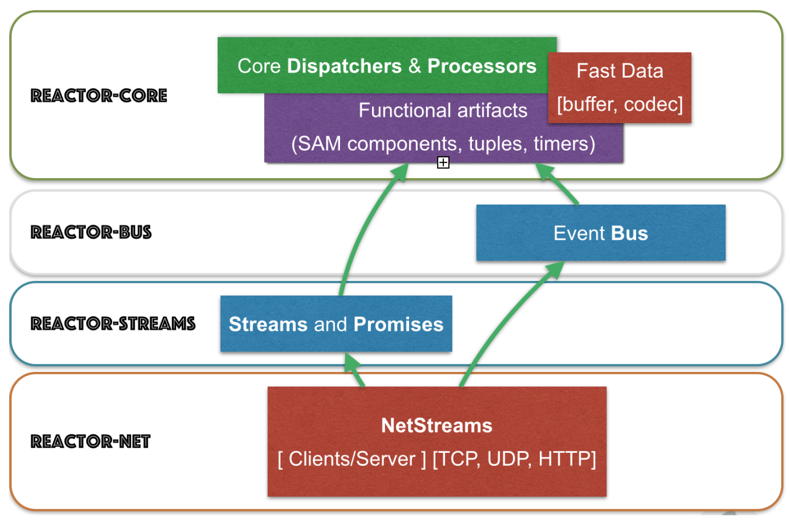
在 Reactor 设计中,最重要的变化是将事件总线和流功能提取到单独的模块中。此外,深度的重新设计使新的 Reactor Streams 库完全符合响应式流规范。Reactor 团队大大改进了 Reactor 的API。例如,新的 Reactor API 与 Java Collections API 具有更好的集成性。
在第二个版本中,Reactor 的 Streams API 变得更加类似于 RxJava API。除了用于创建和消费流的简单附加组件,它还在背压管理、线程调度和回弹性支持方面添加了许多有用的补充。
1.4Project Reactor 3.x版本
Reactor事件总线在2中得到了改进。首先负责发送消息的Reactor对象被重命名为EventBus。该模块也经过重新设计以支持响应式流规范。
Maldini和Karnok将他们对RxJava和Project Reactor的想法和经验浓缩为一个名为reactive-streamcommons的库。后来该库成为Reactor 2.5的基础,并最终演变为Reactor 3.x。
经过一年的努力,Reactor 3.0发布。与此同时,一个完全相同的RxJava 2.0也浮出水面。RxJava与Reactor 3.x的相似性高于与其前身RxJava 1.x的相似性。这些最显著的区别是RxJava针对java6(包括安卓的支持),而Reactor 3选择java8作为基线。同时Reactor 3.x塑造了Spring 5框架的响应式变种。
该库支持所有常见的背压传播模式:
- 仅推送:当订阅者通过subscription.request(Long.MAX_VALUE)请求有效无限数量的元素时。
- 仅拉取:当订阅者通过subscription.request(1)仅在收到前一个元素后请求下一个元素时。
- 拉-推(混合):当订阅者有实时控制需求,且发布者可以适应所提出的数据消费速度时。
为适配不支持推-拉式操作模型的旧API,Reactor提供了许多老式背压机制,包括缓冲、开窗、消息丢弃、启动异常等。
二 Project Reactor核心
2.1 项目中引用
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-core</artifactId>
<version>3.4.0</version>
</dependency>
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-test</artifactId>
<version>3.4.0</version>
</dependency>
2.2 响应式类型——Flux和Mono
响应流规范只定义了4个接口,即
- Publisher
- Subscriber
- Subscription
- Processor<T, R>
Project Reactor提供了Publisher
Flux
上图为将Flux流转换为另一个Flux流的示例。
Flux定义了一个通用的响应式流,它可以产生零个、一个或多个元素,乃至无限元素。
如下代码生成一个简单的无限响应流:
Flux.range(1 1, 5).repeat();订阅者可以随时取消订阅从而将无限流转换为有限流。(收集无限流发出的所有元素会导致OutOfMemoryException )
/** * flux 生成无限流: 最终会导致oom */ @Test public void test1() { // range操作符创建从[1到100]的整数序列 Flux.range(1, 100) // repeat操作符在源流完成之后一次又一次地订阅源响应式流。 // repeat操作符订阅流操作符的结果、接收从1到100的元素以及onComplete信号, // 然后再次订阅、接收,不断重复该过程 .repeat() // 使用collectList操作符尝试将所有生成的元素收集到一个集合中。 // 由于是无限流,最终它会消耗所有内存,导致OOM。 .collectList() // block操作符触发实际订阅并阻塞正在运行的线程,直到最终结果到达 // 当前场景不会发生,因为响应流是无限的。 .block(); }Mono
与Flux相比,Mono类型定义了一个最多可以生成一个元素的流.当应用程序API最多返回一个元素时,可以使用Mono
。 它可以轻松替换CompletableFuture
,并提供相似的语义,只不过CompletableFuture 在没有发出值的情况下无法正常完成。(CompletableFuture 会立即开始处理,而Mono在订阅者出现之前什么也不做) Mono类型不仅提供了大量的响应式操作符,还能够整合到更大的响应式工作流程中。
当需要对已完成的操作通知客户端时,也可以使用Mono。此时,可以返回Mono
类型并在处理完成时发出onComplete() 信号,或者在发生异常时返回onError() 。 Mono和Flux可以容易地相互“转换”。
如:
Flux<T>.collectList() 返回Mono<List<T>>,而Mono<T>.flux()返回Flux<T>RxJava 2响应式类型
即使 RxJava 2.x 库和 Project Reactor 具有相同的基础,RxJava 2 还是有一组不同的响应式发布者。
在版本 2 中,该库具有以下响应式类型:
Observable
与 RxJava 1.x 的Observable语义几乎相同,但是,不接收 null 值。
Observable 既不支持背压,也不实现 Publisher接口,所以它与响应式流规范不直接兼容。
Observable 类型的开销小于 Flowable 类型。
它具有toFlowable 方法,可以通过应用用户选择的背压策略将流转换为 Flowable。
Flowable
Flowable 类型是 Reactor Flux 类型的直接对应物。
实现了响应式流的 Publisher,可以应用在由 Project Reactor 实现的响应式工作流中,因为 API 消费 Publisher 类型的参数,而不是针对特定库的Flux 类型。
Single
Single 类型表示生成且仅生成一个元素的流。
不继承 Publisher 接口。
具有 toFlowable 方法。
不需要背压策略。
相较 Reactor 中的 Mono 类型,Single 更好地表示了 CompletableFuture 的语义,但是在订阅发生之前它仍然不会开始处理。
Maybe
实现了与 Reactor 的 Mono 类型相同的语义,但是不兼容响应式流,因为 Maybe 不实现 Publisher 接口。
具有 toFlowable 方法,以兼容响应式流规范。
Completable
只能触发 onError 或onComplete 信号,但不能产生 onNext 信号。
不实现 Publisher 接口,但具有toFlowable 方法。
它对应不能生成 onNext 信号的 Mono
类型。
2.3 创建Flux和Mono序列
示例代码:demo-2-1
工厂方法:
- Flux.just, Flux.fromArray, Flux.fromIterable, Flux.range …
- Mono.just, Mono.justOrEmpty …
Mono异步操作
- fromCallable(callable)
- fromRunnable(Runnable)
- fromSupplier(Supplier)
- fromFuture(CompletableFuture)
- fromCompletionStage(CompletionStage)
Flux 和 Mono 都可以使用 from(Publisher
p) 工厂方法适配任何其他 Publisher 实例 两种响应式类型都提供了简便的方法来创建常用的空流以及只包含错误的流
Flux<String> empty = Flux.empty();//empty()工厂方法,它们分别生成 Flux 或 Mono 的空实例 FLux<String> never = Flux.never();//never()方法会创建一个永远不会发出完成、数据或错误等信号的流 Mono<String> error = Mono.error(new RuntimeException("url不可达"));
2.4 订阅响应式流
Flux 和 Mono 提供了对 subscribe()方法的基于 lambda 的重载,简化了订阅的开发。
subscribe 方法的所有重载都返回 Disposable接口的实例,可以用于取消基础的订阅过程。
// 重载方法1
// 订阅流的最简单方法,忽略所有信号。通常用于触发具有副作用的流处理。
subscribe();
// 重载方法2
// 对每个值(onNext 信号)调用 dataConsumer,不处理 onError 和 onComplete信号。
subscribe(Consumer<T> dataConsumer);
// 重载方法3
// 与重载方法2相同,处理 onError 信号,忽略 onComplete 信号。
subscribe(Consumer<T> dataConsumer, Consumer<Throwable> errorConsumer);
// 重载方法4
// 与重载方法3相同,处理 onComplete 信号。
subscribe(Consumer<T> dataConsumer, Consumer<Throwable> errorConsumer,
Runnable completeConsumer);
// 重载方法5
// 消费响应式流中的所有元素,包括错误处理和完成信号。重要的是,这种重载方法能通过请求足够数
量的数据来控制订阅,当然,请求数量仍然可以是 Long.MAX_VALUE。
subscribe(Consumer<T> dataConsumer, Consumer<Throwable> errorConsumer,
RUnnable completeConsumer, Consumer<Subscription>
subscriptionConsumer);
// 重载方法6
// 订阅序列的最通用方式。在这里,可以为Subscriber的实现提供所需的行为。
subscribe(Subscriber<T> subscriber);
Tips:
- 响应式流可以由生产者完成(使用 onError 或 onComplete 信号);
- 响应式流可以由订阅者通过 Subscription 实例进行取消。
- Disposable 实例也可用于取消
自定义订阅者示例:
/**
* 自定义订阅者
*/
@Test
public void test8() {
Flux.range(1, 100)
.subscribe(new Subscriber<Integer>() {
private Subscription subscription;
@Override
public void onSubscribe(Subscription s) {
subscription = s;
// 一旦订阅成功,则回调该方法
// 请求一个元素
s.request(1);
}
@Override
public void onNext(Integer integer) {
System.out.println(integer);
subscription.request(1);
}
@Override
public void onError(Throwable t) {
System.out.println(t);
}
@Override
public void onComplete() {
System.out.println("处理结束");
}
});
}
但是,上述定义订阅的方法是不对的。它打破了线性代码流,也容易出错。最困难的部分是需要自己管理背压并正确实现订阅者的所有 TCK 要求。在前面的示例中,打破了有关订阅验证和取消这几个 TCK 要求。
建议扩展 Project Reactor 提供的 BaseSubscriber 类。在这种情况下,订阅者如下所示:
class MySubscriber<T> extends BaseSubscriber<T> {
public void hookOnSubscribe(Subscription subscription) {
System.out.println("订阅成功,开始请求第一个元素");
request(1);
}
public void hookOnNext(T value) {
System.out.println("onNext: " + value);
System.out.println("再次请求一个元素");
request(1);
}
}
BaseSubscriber 类提供了 request(long)和 requestUnbounded()这些方法来对响应式流需求进行粒度控制。
使用 BaseSubscriber 类,实现符合 TCK 的订阅者更为容易。
2.5 用操作符转换响应式流
映射响应式流元素 map
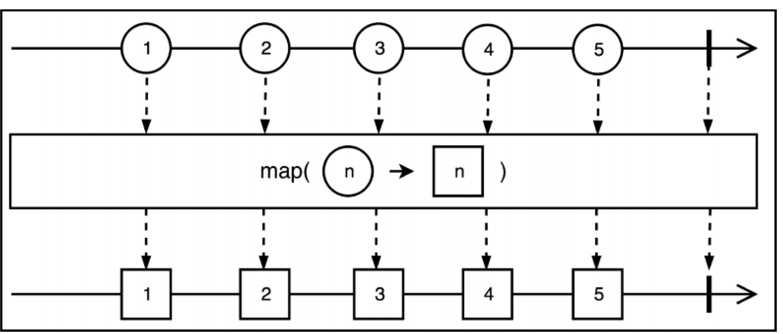
index:可用于枚举序列中的元素
Timestamp:操作符的行为与 index 操作符类似,但会添加当前时间戳而不是索引
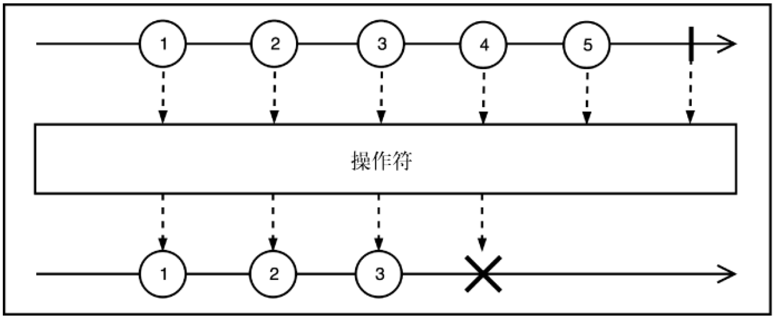
过滤式响应式流
filter 操作符仅传递满足条件的元素。
ignoreElements 操作符返回 Mono
并过滤所有元素。结果序列仅在原始序列结束后结束。 take(n) 操作符限制所获取的元素,该方法忽略除前 n 个元素之外的所有元素。
takeLast 仅返回流的最后一个元素。
takeUntil(Predicate) 传递一个元素直到满足某个条件。
elementAt(n) 只可用于获取序列的第 n 个元素。
single 操作符从数据源发出单个数据项,也为空数据源发出 NoSuchElementException错误信号,或者为具有多个元素的数据源发出IndexOutOfBoundsException 信号。它不仅可以基于一定数量来获取或跳过元素,还可以通过带有Duration的skip(Duration) 或take(Duration) 操作符。
takeUntilOther(Publisher) 或 skipUntilOther(Publisher) 操作符,可以跳过或获取一个元素,直到某些消息从另一个流到达。
收集式响应式流
收集列表中的所有元素,并使用 Flux.collectList() 和 Flux.collectSortedList() 将结果集合处理为 Mono 流是可能的。Flux.collectSortedList() 不仅会收集元素,还会对它们进行排序。
请注意,收集集合中的序列元素可能耗费资源,当序列具有许多元素时这种现象尤为突出。此外,尝试在无限流上收集数据可能消耗所有可用的内存。
使用 collectMap 操作符的映射( Map<K,T> );
使用 collectMultimap 操作符的多映射( Map<K,Collection
> ); Flux.collect(Collector) 操作符收集到任何实现了java.util.stream.Collector 的数据结构。
Flux 和 Mono 都有 repeat() 方法和 repeat(times) 方法,这两种方法可以针对传入序列进行循环操作。
defaultIfEmpty(T) 是另一个简洁的方法,它能为空的 Flux 或 Mono 提供默认值。
Flux.distinct() 仅传递之前未在流中遇到过的元素。但是,因为此方法会跟踪所有唯一性元素,所以(尤其是涉及高基数数据流时)请谨慎使用。distinct 方法具有重载方法,可以为重复跟踪提供自定义算法。因此,有时可以手动优化 distinct 操作符的资源使用。Flux.distinctUntilChanged() 操作符没有此限制,可用于无限流以删除出现在不间断行中的重复项。
**高基数(high-cardinality)**是指具有非常罕见元素或唯一性元素的数据。例如,身份编号和用户名就是典型的高基数数据,而枚举值或来自小型固定字典的值就不是。
裁剪式响应式流
统计流中元素的数量;
检查所有元素是否具有 Flux.all(Predicate) 所需的属性;
使用 Flux.any(Predicate) 操作符检查是否至少有一个元素具有所需属性;
使用 hasElements 操作符检查流中是否包含多个元素;
使用 hasElement 操作符检查流中是否包含某个所需的元素。短路逻辑,在元素与值匹配时立即返回true。
any 操作符不仅可以检查元素的相等性,还可以通过提供自定义 Predicate 实例来检查任何其
他属性。
等
组合响应式流
concat 操作符通过向下游转发接收的元素来连接所有数据源。当操作符连接两个流时,它首先消费并重新发送第一个流的所有元素,然后对第二个流执行相同的操作。
merge 操作符将来自上游序列的数据合并到一个下游序列中。与 concat 操作符不同,上游数据源是立即(同时)被订阅的。
zip 操作符订阅所有上游,等待所有数据源发出一个元素,然后将接收到的元素组合到一个输出元素中。
combineLatest 操作符与 zip 操作符的工作方式类似。但是,只要至少一个上游数据源发出一个值,它就会生成一个新值。
批处理
将元素缓冲(buffering)到容器(如 List)中,结果流的类型为 Flux<List
> 。 通过开窗(windowing)方式将元素加入诸如 Flux<Flux
> 等流中。请注意,现在的流信号不是值,而是可以处理的子流。 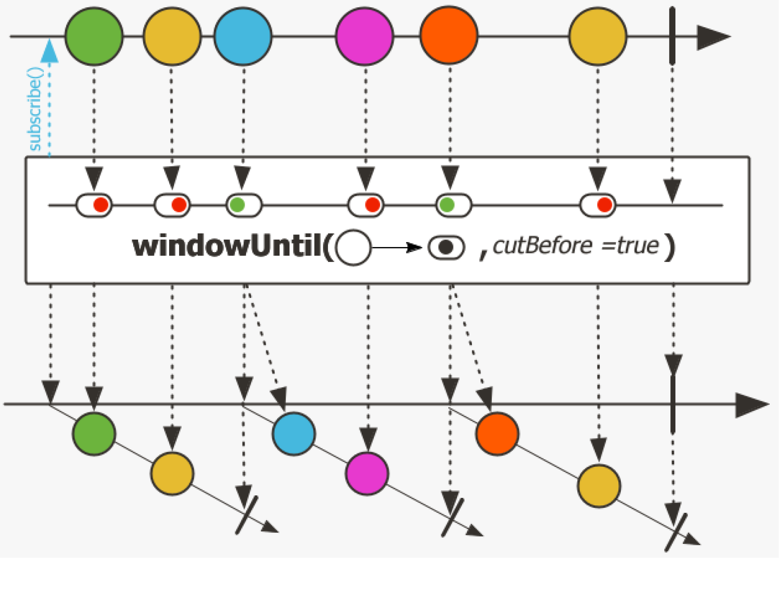
通过某些键将元素分组(grouping)到具有 Flux<GroupedFlux<K, T» 类型的流中。每个新键都会触发一个新的 GroupedFlux 实例,并且具有该键的所有元素都将被推送到GroupFlux 类的该实例中。
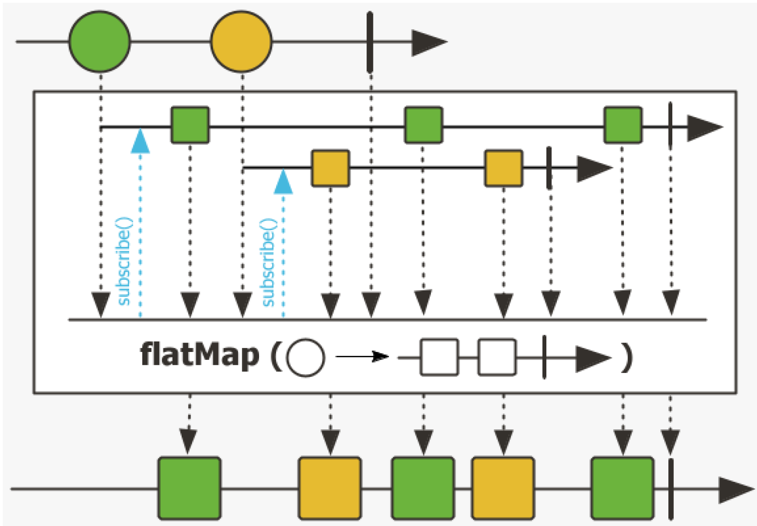
flatMap、concatMap 和 flatMapSequential 操作符
flatMap 操作符在逻辑上由 map 和 flatten(就 Reactor 而言,flatten 类似于 merge 操作符)这两个操作组成。
flatMap 操作符的 map 部分将传入的每个元素转换为响应式流(T -> Flux
); flatten 部分将所有生成的响应式流合并为一个新的响应式流,通过该流可以传递 R 类型的元素
这 3 个操作符在以下几个方面有所不同。
操作符是否立即订阅其内部流;
flatMap 操作符和 flatMapSequential 操作符会立即订阅,而 concatMap 操作符则会在生成下一个子流并订阅它之前等待每个内部完成。
操作符是否保留生成元素的顺序;
concatMap 天生保留与源元素相同的顺序,flatMapSequential 操作符通过对所接收的元素进行排序来保留顺序,而 flatMap 操作符不一定保留原始排序。
操作符是否允许对来自不同子流的元素进行交错;
flatMap 操作符允许交错,而 concatMap和 flatMapSequential 不允许交错。
元素采样
对于高吞吐量场景而言,通过应用采样技术处理一小部分事件是有意义的
sample 操作符和 sampleTimeout 操作符可以让流周期性地发出与时间窗口内最近看到的值相对应的数据项。
将响应式流转化为阻塞结构
有以下选项来阻塞流并同步生成结果:
toIterable 方法将响应式 Flux 转换为阻塞 Iterable。
toStream 方法将响应式 Flux 转换为阻塞 Stream API。从 Reactor 3.2 开始,在底层使用toIterable 方法。
blockFirst 方法阻塞了当前线程,直到上游发出第一个值或完成流为止。
blockLast 方法阻塞当前线程,直到上游发出最后一个值或完成流为止。在 onError的情况下,它会在被阻塞的线程中抛出异常。
在序列处理时查看元素
doOnNext(Consumer
) 使我们能对 Flux 或 Mono 上的每个元素执行一些操作。 doOnComplete 和 doOnError(Throwable) 可以应用在相应的事件上。
doOnSubscribe(Consumer
) 、 doOnRequest(LongConsumer) 和doOnCancel(Runnable) 使我们能对订阅生命周期事件做出响应。 无论是什么原因导致的流终止, doOnTerminate(Runnable) 都会在流终止时被调用
物化和非物化信号
将流中的元素封装为Signal对象进行处理。
有时,采用信号进行流处理比采用数据进行流处理更有用。为了将数据流转换为信号流并再次返回,Flux 和 Mono 提供了 materialize 方法和 dematerialize 方法
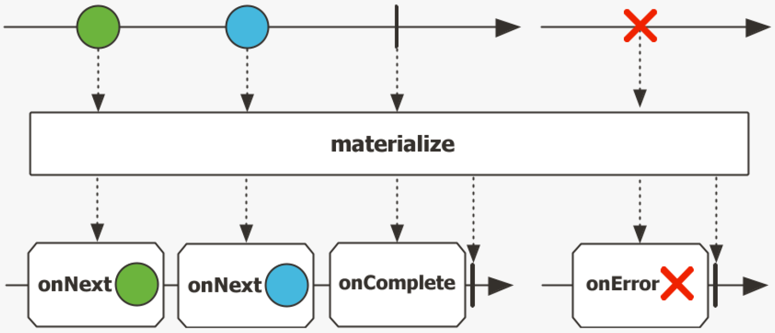
这里,在处理信号流时,doOnNext 方法不仅接收带有数据的 onNext 事件,还接收包含在Signal类中的 onComplete 事件。此方法能采用一个类型层次结构来处理 onNext、onError和 onCompete 事件
2.6 以编程方式创建流
示例代码:demo-2-2
有时候需要一种更复杂的方法来在流中生成信号,或将对象的生命周期绑定到响应式流的生命周期。
push 和 create 工厂方法
push方法对于适配异步、单线程、多值 API 非常有用,而无须关注背压和取消, push 方法本身包含背压和取消
create 工厂方法,与 push 工厂方法类似,起到桥接的作用, 该方法能从不同的线程发送事件
push与create官方文档 https://projectreactor.io/docs/core/release/api/reactor/core/publisher/Flux.html
generate 工厂方法
generate 工厂方法旨在基于生成器的内部处理状态创建复杂序列。
它需要一个初始值和一个函数,该函数根据前一个内部状态计算下一个状态,并将 onNext 信号发送给下游订阅者。
在下一个值生成之前,每个新值都被同步传播给订阅者。
using 工厂方法
using 工厂方法能根据一个 disposable 资源创建流。它在响应式编程中实现了 try-withresources方法。
usingWhen 工厂包装响应式事务
与 using 操作符类似,usingWhen 操作符使我们能以响应式方式管理资源。但是,using操作符会同步获取受托管资源(通过调用 Callable 实例)。同时,usingWhen 操作符响应式地获取受托管资源(通过订阅 Publisher 的实例)。此外,usingWhen 操作符接受不同的处理程序,以便应对主处理流终止的成功和失败。这些处理程序由发布者实现。
使用 usingWhen 操作符,不仅可以更容易地以完全响应式的方式管理资源生命周期,还可以轻松实现响应式事务。
因此,与 using 操作符相比,usingWhen 操作符有巨大改进。
2.7 错误处理
onError 信号是响应式流规范的一个组成部分,一种将异常传播给可以处理它的用户。但是,如果最终订阅者没有为 onError 信号定义处理程序,那么 onError 抛异常
此外,响应式流的语义定义了 onError 是一个终止操作,该操作之后响应式流会停止执行。
此时,我们可能采取以下策略中的一种做出不同响应:
- 为 subscribe 操作符中的 onError 信号定义处理程序。
- 通过 onErrorReturn 操作符捕获一个错误,并用一个默认静态值或一个从异常中计算出的值替换它。
- 通过 onErrorResume 操作符捕获异常并执行备用工作流。
- 通过 onErrorMap 操作符捕获异常并将其转换为另一个异常来更好地表现当前场景。
- 定义一个在发生错误时重新执行的
假设有如下推荐服务,该服务是不可靠的:
private static Random random = new Random();
public static Flux<String> recommendedBooks(String userId) {
return Flux.defer(() -> {
if (random.nextInt(10) < 7) {
return Flux.<String>error(new RuntimeException("Err"))
// 整体向后推移指定时间,元素发射频率不变
.delaySequence(Duration.ofMillis(100));
} else {
return Flux.just("Blue Mars", "The Expanse")
.delayElements(Duration.ofMillis(50));
}
}).doOnSubscribe(
item -> System.out.println("请求:" + userId)
);
}
示例代码:demo-2-2
2.8背压处理
尽管响应式流规范要求将背压构建到生产者和消费者之间的通信中,但这仍然可能使消费者溢出。
一些消费者可能无意识地请求无界需求,然后无法处理生成的负载。
另一些消费者则可能对传入消息的速率有严格的限制。例如,数据库客户端每秒不能插入超过 1000条记录。在这种情况下,事件批处理技术可能有所帮助。
可以通过以下方式配置流以处理背压情况:
- onBackPressureBuffer 操作符会请求无界需求并将返回的元素推送到下游。如果下游消费者无法跟上,那么元素将缓冲在队列中。
- onBackPressureDrop 操作符也请求无界需求(Integer.MAX_VALUE)并向下游推送数据。如果下游请求数量不足,那么元素会被丢弃。自定义处理程序可以用来处理已丢弃的元素。
- onBackPressureLast 操作符与 onBackPressureDrop 的工作方式类似。只是会记住最近收到的元素,并在需求出现时立即将其推向下游。
- onBackPressureError 操作符在尝试向下游推送数据时请求无界需求。如果下游消费者无法跟上,则操作符会引发错误。
管理背压的另一种方法是使用速率限制技术
- limitRate(n) 操作符将下游需求拆分为不大于 n的较小批次。可以保护脆弱的生产者免受来自下游消费者的不合理数据请求的破坏。limitRate(n) 操作符会限制来自下游消费者的需求(总请求值)。
2.9 热数据流和冷数据流
**冷发布者行为方式:**无论订阅者何时出现,都为该订阅者生成所有序列数据,没有订阅者就不会生成数据。
热发布者: 数据生成不依赖于订阅者而存在。因此,热发布者可能在第一个订阅者出现之前开始生成元素。
这种语义代表数据广播场景。例如,一旦股价发生变化,热发布者就可以向其订阅者广播有关当前股价的更新。
但是,当订阅者到达时,它仅接收未来的价格更新,而不接受先前价格历史。Reactor 库中的大多数热发布者扩展了 Processor 接口。但是,just 工厂方法会生成一个热发布者,因为它的值只在构建发布者时计算一次,并且在新订阅者到达时不会重新计算。
可以通过将 just 包装在 defer 中来将其转换为冷发行者。这样,即使 just 在初始化时生成值,这种初始化也只会在新订阅出现时发生。后一种行为由 defer 工厂方法决定。
多播流元素
通过响应式转换将冷发布者转变为热发布者
如,一旦所有订阅者都准备好生成数据,希望在几个订阅者之间共享冷处理器的结果。同时,我们又不希望为每个订阅者重新生成数据。Project Reactor为此目的提供了 ConnectableFlux
ConnectableFlux ,不仅可以生成数据以满足最急迫的需求,还会缓存数据,以便所有其他订阅者可以按照自己的速度处理数据。队列和超时的大小可以通过类的 publish 方法和 replay 方法进行配置。
此外, ConnectableFlux 可以使用 connect 、autoConnect(n) 、refCount(n) 和refCount(int,Duration) 等方法自动跟踪下游订阅者的数量,以便在达到所需阈值时触发执行操作。
缓存流元素
使用 ConnectableFlux 可以轻松实现不同的数据缓存策略。但是,Reactor 已经以 cache 操作符的形式提供了用于事件缓存的 API。
cache 操作符使用 ConnectableFlux ,因此它的主要附加值是它所提供的一个流式而直接的API。
可以调整缓存所能容纳的数据量以及每个缓存项的到期时间。
共享流元素
我们可以使用 ConnectableFlux 向几个订阅者多播事件。但是需要等待订阅者出现才能开始处理。
share 操作符可以将冷发布者转变为热发布者。该操作符会为每个新订阅者传播订阅者尚未错过的事件。
2.10 处理时间
响应式编程是异步的,因此它本身就假定存在时序。
基于 Project Reactor
- interval 生成基于一定持续时间的事件
- delayElements 生成延迟元素
- delaySequence 延迟所有信号
- timestamp 输出元素的时间戳
- timeout 指定消息时间间隔的大小
- elapsed 测量与上一个事件的时间间隔
示例代码:demo-2-2
2.11 组合和转换响应式流
当我们构建复杂的响应式工作流时,通常需要在几个不同的地方使用相同的操作符序列。
transform 操作符
可以将这些常见的部分提取到单独的对象中,并在需要时重用它们。可以增强流结构本身。
transform 操作符仅在流生命周期的组装阶段更新一次流行为,可以在响应式应用程序中实现代码重用
2.12 处理器
响应式流规范定义了 Processor 接口。Processor 既是 Publisher 也是 Subscriber。
因此,既可以订阅 Processor 实例,也可以手动向它发送信号(onNext、onError 和onComplete)。
Reactor 的作者建议忽略处理器,因为它们很难使用并且容易出错。
在大多数情况下,处理器可以被操作符的组合所取代。另外,生成器工厂方法(push、create 和generate)可能更适合适配外部 API。
Direct 处理器
只能通过操作处理器的接收器来推送因用户手动操作而产生的数据。
DirectProcessor 和 UnicastProcessor 是这组处理器的代表。
DirectProcessor 不处理背压,可用于向多个订阅者发布事件。
UnicastProcessor 使用内部队列处理背压,最多只能为一个 Subscriber 服务。
Synchronous 处理器
EmitterProcessor 和 ReplayProcessor 可以同时通过手动方式和订阅上游Publisher 的方式来推送数据。
EmitterProcessor 可以为多个订阅者提供服务并满足它们的需求,但仅能以同步方式消费由单一 Publisher 产生的数据。
ReplayProcessor 的行为类似于EmitterProcessor ,但是它能使用几种策略来缓存传入的数据。
Asynchronous 处理器
WorkQueueProcessor 和 TopicProcessor 可以推送从多个上游发布者处获得的下游数据。
为了处理多个上游发布者,这些处理器使用 RingBuffer数据结构。这些处理器具有专用的构建器 API,因为配置选项的数量使它们很难初始化。
TopicProcessor 兼容响应式流,并可以为每个下游 Subscriber 关联一个 Thread来处理交互。它可以服务的下游订阅者数量有限。
WorkQueueProcessor 具有与 TopicProcessor 类似
2.13. 测试和调试Project Reactor
Reactor 库附带了一个通用的测试框架。io.projectreactor:reactor-test 库提供了测试Project Reactor 所实现的响应式工作流所需的所有必要工具。
虽然响应式代码不那么容易调试,但是 Project Reactor 提供了能在需要时简化调试过程的技术。与任何基于回调的框架一样,Project Reactor 中的栈跟踪信息量不大。它们没有在代码中给出发生异常情况的确切位置。Reactor 库具有面向调试的组装时检测功能,可以使用以下代码激活:Hooks.1 onOperatorDebug();
启用后,此功能开始收集将要组装的所有流的栈跟踪,稍后此信息可以基于组装信息扩展栈跟踪信息,从而帮助我们更快地发现问题。但是,创建栈跟踪的过程成本很高。因此,作为最后的手段,它应该只以受控的方式进行激活。
此外,Project Reactor 的 Flux 和 Mono 类型提供了一个被称为 log 的便捷方法。它能记录使用操作符的所有信号。即使在调试情况下,许多方法的自定义实现也可以提供足够的自由度来跟踪所需的数据
示例代码:demo-2-2
2.14 Reactor 插件
Project Reactor 是一个通用且功能丰富的库。但是,它无法容纳所有有用的响应式工具。因此,有一些项目在一些领域扩展了 Reactor 的功能。官方的 Reactor 插件项目为 Reactor 项目提供了几个模块。
reactor-adapter
为 RxJava 2 响应式类型和调度程序提供桥接。此外,该模块还能与Akka 进行集成
<dependency> <groupId>io.projectreactor.addons</groupId> <artifactId>reactor-adapter</artifactId> <version>3.4.0</version> </dependency>reactor-logback
提供高速异步日志记录功能。它以 Logback 的 AsyncAppender和 LMAXDisruptor 的 RingBuffer 为基础,其中后者通过 Reactor 的 Processor 实现。
<dependency> <groupId>io.projectreactor.addons</groupId> <artifactId>reactor-logback</artifactId> <version>3.2.6.RELEASE</version> </dependency>reactor-extra
包含用于高级需求的其他实用程序。例如,该模块包含 TupleUtils类,该类简化了编写 Tuple 类的代码。此外,该模块具有 MathFlux类,可以从数字源中计算最小值和最大值,并对它们求和或取平均。ForkJoinPoolScheduler 类使 Java 的 ForkJoinPool 适配 Reactor 的Scheduler。
<dependency> <groupId>io.projectreactor.addons</groupId> <artifactId>reactor-extra</artifactId> <version>3.4.0</version> </dependency>
引外,还有Reactor RabbitMQ、Reactor Kafka、Reactor Netty等
三、Project Reactor高级
3.1 响应式流的生命周期
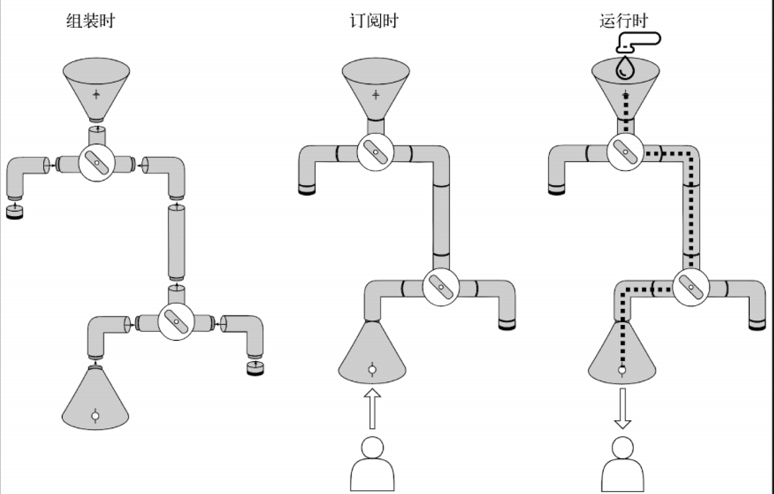
组装时
流生命周期的第一部分是组装时(assembly-time)
Reactor 提供了一个流式 api,用于构建复杂的元素处理流程,其看起来更像一个建造器。响应式库中,构建执行流程的过程被称为“组装”。
在底层,Flux 对象是相互组合的。在组装过程之后,就获得了一个 Publishers 链,每个新的Publisher 包装了前一个。
在流生命周期中,该阶段起着重要作用,因为在流组装期间,可以通过检查流的类型来一个接一个地替换操作符。
此外,在组装时,可以在组装过程中为流提供一些 Hooks,并启用一些额外的日志记录、跟踪、度量收集,以及其他在调试或流监控期间可能有用的重要补充。
在该阶段,可以操作流的构造过程并应用不同的技术来优化、监控或更好地进行流调试,这是构建响应式流必不可少的部分。
订阅时
流执行生命周期的第二个重要阶段是订阅时(subscription-time)。
当调用指定的Publisher的subscribe方法时,就会发生订阅。
为了构建执行流程,对 Publishers 进行相互传递,因而产生了 Publishers 链。一旦调用了顶层包装器的subscribe方法,就开始了该链的订阅过程。
订阅时阶段的重要性在于:
在该阶段中,可以执行与组装时阶段相同的优化。
其次,在 Reactor 中启用多线程的一些操作符能够更改订阅所发生的工作单元。
运行时
流执行的最后一步是运行时(runtime)阶段。
在该阶段,在 Publisher 和 Subscriber之间进行实际信号交换。
响应式流规范规定,Publisher 和 Subscriber 交换的前两个信号是 onSubscribe 信号和 request 信号。
在运行时,数据源中的元素通过 Subscriber 链,并在每个阶段执行不同的功能。在运行时我们可以应用优化,减少信号交换量。
3.2 Reactor中的线程调度模型
publishOn 操作符
publishOn 操作符能将部分运行时操作的执行移动到指定的工作单元。
为了指定应该在运行时处理元素的工作单元,Reactor 为此引入了一个特定的抽象,叫作Scheduler。Scheduler 是一个接口,代表 Project Reactor 中的一个工作单元或工作单元池。
publishOn 操作符之后的执行位于不同的 Scheduler 工作单元上。这意味着对散列的计算发生在Thread A 上,因此 calculateHash 和 doBusinessLogic 在与 Thread Main 不同的工作单元上执行。如果从执行模型角度来看 publishOn 操作符,可以得到下图所示流程。
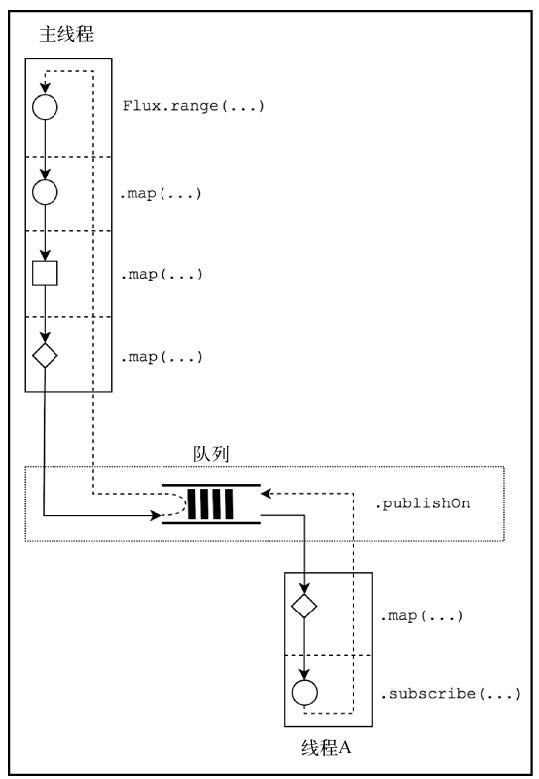
publishOn 操作符的重点是运行时执行。在底层,publishOn 操作符会保留一个队列,并为该队列提供新元素,以便专用工作单元消费消息并逐个处理它们。
该示例表明工作正在单独的 Thread 上运行,因此其执行被一个异步边界所分割。所以,现在有两部分独立处理的流程。
注意:响应式流中的所有元素都是逐个处理的(而不是同时处理的),因此可以始终为所有事件定义严格的顺序。此属性也被称为串行化(serializability)。
即,元素一旦进入 publishOn,就将被放入队列,并且一旦轮到它,它就将被移出队列进行处理。
注意,由于只有一个工作单元专门负责处理队列,因而元素的顺序始终是可预测的。
使用publishOn操作符实现并行化
Project Reactor 提供的响应式编程范例可以使用 publishOn 操作符对处理流进行细粒度伸缩和并行化等处理
如下过程:有一个处理流程,其中包含 3 个元素。由于流中元素的同步处理特性,必须在所有转换阶段中逐个移动元素。但是,为了开始处理下一个元素,必须完全处理完前一个元素。
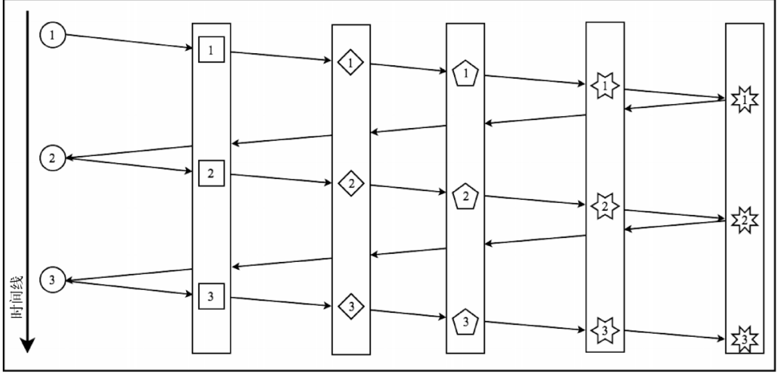
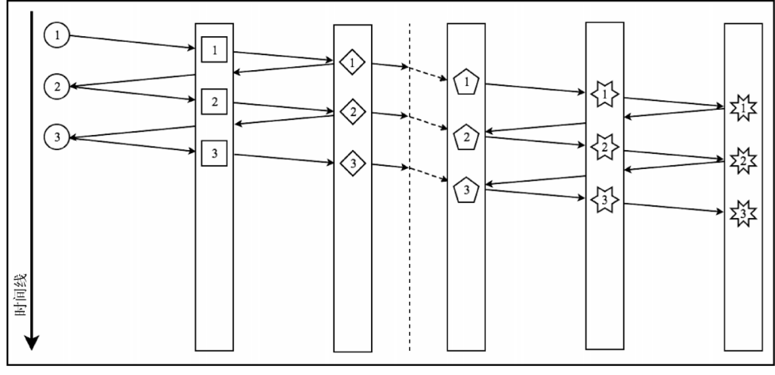
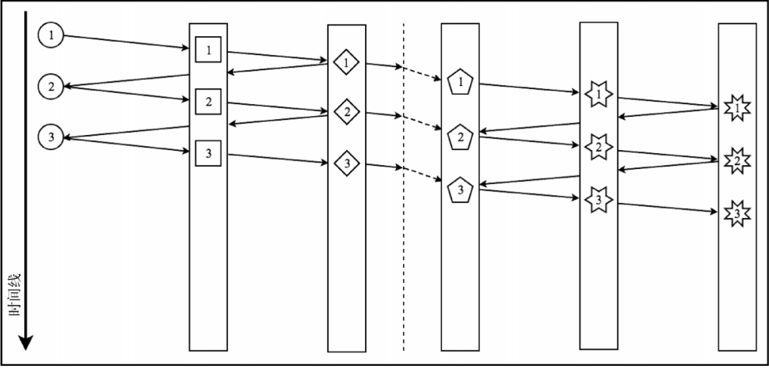
如果在这个流程中放置一个 publishOn,就可能加快处理速度
subscribeOn操作符
Reactor 中多线程的另一个要点是名为 subscribeOn 的操作符。与 publishOn 相比,subscribeOn使你能更改正在运行的订阅链的工作单元。当从函数的执行过程中创建流的数据源时,此操作符很有用。通常,此类执行在订阅时进行,它会调用一个函数,该函数会提供执行.subscribe 方法的数据源。如下:
ObjectMapper objectMapper = ... String json = "{ \"color\" : \"Black\", \"type\" : \"BMW\" }"; Mono.fromCallable(() -> objectMapper.readValue(json, Car.class)) // ...这里, Mono.fromCallable 从 Callable
创建 Mono ,并将其评估结果提供给每个Subscriber 。Callable 实例在调用 subscribe 方法时执行。因此 Mono.fromCallable 在底层执行以下操作: public void subscribe(Subscriber actual) { // 准备Subscription对象 Subscription subscription = ... try { // 调用call方法,获取数据元素 T t = callable.call(); if (t == null) { // 如果没有数据,直接调用onComplete方法,结束响应式流 subscription.onComplete(); } else { // 如果有数据,则调用订阅票据的onNext方法传递元素。 subscription.onNext(t); // 由于是Mono,传递一个元素之后,调用onComplete方法,结束响应式流 subscription.onComplete(); } } catch (Throwable e) { actual.onError( Operators.onOperatorError(e, actual.currentContext()) ); } }Callable 的执行发生在 subscribe 方法中。
可以使用subscribeOn 指定进行订阅的工作单元。
并行操作符
除了一些重要操作符(用于管理想要处理的执行流某些部分的线程),Reactor 还提供了一种熟悉的并行工作技术。为此,Reactor 有一个名为 parallel 的操作符,它能将流分割为并行子流并均衡它们之间的元素。
Random random = new Random(); CountDownLatch latch = new CountDownLatch(1); Flux.range(1, 10000) .parallel() // 轮询方式将元素交给各个处理器核心来处理,这里只是准备阶段,需要调用runOn真正调度执行。 .doOnNext(item -> { System.out.println("parallel:" + Thread.currentThread().getName()); }) .runOn(Schedulers.parallel()) // 每个处理器核心一个执行单元。4c8t,线程名称:runOn:parallel-{1-8} .doOnNext(item -> { System.out.println("runOn:" + Thread.currentThread().getName()); }) .map(num -> num + random.nextInt(10000)) // 4c8t,线程名称:runOn:parallel-{1-8} .doOnNext(item -> { System.out.println("map:" + Thread.currentThread().getName()); }) .filter(num -> num % 2 == 0) // 某些核心执行单元的数字被过滤掉了 .doOnNext(item -> { System.out.println("filter:" + Thread.currentThread().getName()); }) .subscribe( // 执行在上述各自线程中 item -> System.out.println(Thread.currentThread().getName()+ ":" + item), ex -> System.err.println(ex), () -> latch.countDown() ); latch.await();parallel() 是 Flux API 的一部分。通过应用 parallel 操作符,开始在不同类型的 Flux 上执行操作,该 Flux 被称为 ParallelFlux 。
ParallelFlux 是一组 Flux 的抽象,其中源 Flux 中的元素是均衡的。然后,通过应用 runOn操作符,可以将 publishOn 应用于内部 Flux,并分配与元素(正在不同工作单元之间进行处理)相关的工作。
调度器
调度器是一个接口,具有两个核心方法,即 Scheduler.schedule 和Scheduler.createWorker。
第一个方法可以调度 Runnable 任务;第二个方法不仅为我们提供了 Worker 接口的专用实例,还可以以相同的方式调度 Runnable 任务。Scheduler 接口和 Worker 接口之间的核心区别在于Scheduler 接口表示工作单元池,而 Worker 是 Thread 或资源的专用抽象。
默认情况下,Reactor 提供 3 个核心调度程序接口实现。
SingleScheduler 能为一个专用工作单元安排所有可能的任务。它具有时间性,因此可以延迟安排定期事件。此调度程序可以使用 Scheduler.single()调用进行引用。
ParallelScheduler 适用于固定大小的工作单元池(默认情况下,其大小受 CPU 内核数限制)。适合 CPU密集型任务。此外,默认情况下,它也处理与时间相关的调度事件,例如Flux.interval(Duration.ofSeconds(1))。此调度程序可以使用 Scheduler.parallel()调用进行引用。
ElasticScheduler 可以动态创建工作单元并缓存线程池。由于其所创建的线程池没有最大数量限制,因此此调度程序非常适用于 I/O 密集型操作的调度。此调度程序可以使用Scheduler.elastic()调用进行引用。
此外,还可以实现具有所期望的特性的 Scheduler。
响应式上下文
Reactor 附带的另一个关键功能是 Context。Context 是沿数据流传递的接口。
Context接口的核心思想是提供对某些上下文信息的访问,因为这些信息可能在稍后的运行时阶段有用。
既然已经有了可以做同样工作的 ThreadLocal,为什么还需要这个功能?例如,许多框架使用ThreadLocal 来沿用户请求执行传递 SecurityContext,以在任何处理点访问授权用户。
只是,这种概念只有在进行单线程处理时才能正常工作,因为执行是依附于同一个 Thread。如果开始在异步处理中使用该概念,那么 ThreadLocal 将会非常快速地释放。
在多线程环境中使用 ThreadLocal 是非常危险的,并且可能导致意外行为。尽管 Java API 能将ThreadLocal 数据从一个 Thread 传输到另一个 Thread,但它并不保证传输的完全一致性。
Reactor Context 通过以下方式解决了这个问题:
Flux.range(0, 10) .flatMap( k -> Mono.subscriberContext() .doOnNext( context -> { Map<Object, Object> map = context.get("randoms"); map.put(k, new Random(k).nextGaussian()); } ).thenReturn(k) ) .publishOn(Schedulers.parallel()) .flatMap( k -> Mono.subscriberContext() .map( context -> { Map<Object, Object> map = context.get("randoms"); return map.get(k); } ) ) .subscriberContext( context -> context.put("randoms", new HashMap()) ) .blockLast();Reactor 使用静态操作符 subscriberContext 提供对当前流中 Context 实例的访问。一旦获取了 Context,就可以访问 Map 并将生成的值放在那里。最后,返回 flatMap 的初始参数。
在切换 Thread 后再次访问 Reactor 的 Context。尽管此示例与使用ThreadLocal 的前一个示例相同,但将成功获取存储的映射并获得生成的随机高斯双精度数。
最后,在这里,为了生成 randoms 键(该键返回一个 Map),我们在上游填充一个新的Context 实例,该实例包含所需键对应的 Map。
Context 可以通过无参数的 Mono.subscriberContext 操作符进行访问,并且可以通过单参数subscriberContext(Context) 操作符提供给流。
既然 Context 接口具有与 Map 接口类似的方法,那为什么需要使用 Map 来传输数据?
Context 是不可变对象,一旦向它添加新元素,就实现了 Context 的新实例。这样的设计决策有利于多线程访问模型。
这意味着,这是向流提供 Context 并动态提供某些数据的唯一方法,这些数据将在组装时或订阅时的整个运行执行期间可用。如果在组装时提供了 Context,那么所有订阅者将共享相同的静态上下文,但这在每个 Subscriber(可能代表用户连接)具有其自身的 Context 的情况下可能没有用。因此,可以向每个 Subscriber 提供其自身上下文的唯一生命周期时段是订阅时阶段。
在订阅时,Subscriber 通过 Publisher 链从流的底部上升到顶部,并在每个阶段中形成包装到本地 Subscriber 的表现形式,从而引入额外的运行时逻辑。为了保持该流程不变并通过流传递额外的 Context 对象,Reactor 使用名为 CoreSubscriber 的接口,该接口是 Subscriber 接口的特定扩展。 CoreSubscriber 将 Context 作为其字段进行传递
3.3 Project Reactor内幕
Reactor 拥有丰富的有用操作符。整个 API 具有与 RxJava 类似的操作符。
Project Ractor 3 最显著的改进是:响应式流生命周期(Reactive Stream life-cycle)和操作符融合(operator fusion)。
宏融合
宏融合(macro-fusion)主要发生在组装时,其目的是用一个操作符替换另一个操作符。
同时,Flux 内部操作符的某些部分也应该处理一个或零个元素(例如,操作符 just(T)、empty()和error(Throwable))。
微融合
微融合(micro-fusion)是一种更复杂的优化,与运行时优化以及重用共享资源有关。微融合的一个很好的例子是条件操作符。