响应式编程概述
示例代码:https://gitee.com/ixinglan/spring-webflux-demo.git
1.响应式编程介绍
1.1 为什么需要响应式
传统的命令式编程在面对当前的需求时的一些限制 例:有需求,即使在应用负载较高时,应用需要有更高的可用性,并提供低的延迟时间
Thread per Request模型
比如使用Servlet开发的单体应用,部署到tomcat。
tomcat有线程池,每个请求交给线程池中的一个线程来执行,如果执行过程中包括访问数据库,或者包括读取文件,则在调用数据库时或读取文件时,请求线程是阻塞的,即使是阻塞线程也是占用资源的,典型的每个线程要使用1MB的内存。
如果有并发请求,则会同时有多个线程处于阻塞状态,每个线程占据一份资源。同时,Tomcat的线程池大小决定了可以同时处理多少个请求。
传统的方式:使用Spring MVC开发web应用并部署到Servlet容器,如Tomcat。 Servlet容器有专门的线程池用于管理HTTP请求,每个请求对应一个线程,该线程负责该请求的整个生命周期(Thread per Request模型)。意味着应用仅能处理并发数为线程池大小的请求。可以配置更大的线程池,但是线程占用内存(一般一个线程1MB的样子),线程数越多,占用的内存越大。
如果应用基于微服务架构,我们可以做横向扩展,但是也有内存高占用的问题。因此,当并发数很大的时候,Thread per Request模型很消耗资源。
微服务架构一个特性是分布式,运行很多分立的进程(很多服务器)。传统的命令式编程使用同步 的请求/响应模式在服务之间通信,线程需要频繁的在服务调用的时候阻塞。浪费了资源。等待I/O操作
在I/O操作中也存在大量的资源浪费:如调用数据库,读取文件等
响应延迟
传统命令式编程另一个问题是:当一个服务需要做很多操作而不仅仅是I/O请求的时候,响应延迟相应的增大
压垮客户端
微服务的另一个问题是:服务A请求服务B的数据,如果数据量很大,超过了服务A能处理的程度,则导致服务OOM。
响应式编程的优势:
- 不用Thread per Request模型,使用少量线程即可处理大量的请求。
- 在执行I/O操作时不让线程等待。
- 简化并行调用。
- 支持背压,让客户端告诉服务端它可以处理多少负载。
响应式编程是使用异步、事件驱动构建非阻塞式应用的,此类应用仅需要少量的线程用于横向扩展。即使用异步数据流编程。
响应式系统设计目标:
- 响应性,以时序的方式响应
- 健壮,即使发生错误也可以保证响应性
- 弹性,在不同的工作负载下保持响应性
- 消息驱动,依赖异步消息传递机制
1.2 响应性应用安全
响应式编程是使用异步数据流进行编程
流是一个时序事件序列,可以发射三种不同的事件:(某种类型的)值、错误或者一个完成信号。分别为值、错误、完成定义事件处理函数,异步地处理事件。
监听一个流称为订阅,定义的函数是观察者,流是被观察者,即观察者模式。
1.3 响应式现状
2011年,微软发布了.NET的响应式扩展(Reactive Extensions,即ReactiveX或Rx),以方便异步、事件驱动的程序。
ReactiveX混合了迭代器模式和观察者模式。不同之处在于一个是推模式,一个是基于迭代器的拉模式。
响应式扩展被移植到几种语言和平台上,包括 JavaScript、Python、C++、Swift和java。ReactiveX很快成为一种跨语言的标准,将响应式编程引入到行业中。
RxJava,是 Java 的 ReactiveX 实现,很大程度上由 Netflix 的 bench ristensen 和 david karnok创建的。
RxJava 1.0于2014年11月发布。
RxJava是其他reactivex jvm平台技术的主要技术,其他的如如RxScala、RxKotlin、RxGroovy。RxJava已经成为Android开发的核心技术,并且已经进入Java后端开发。
许多RxJava adapter库,例如RxAndroid,RxJava JDBC,RxNetty, 和RxJavaFX调整了几个Java框架,使之成为响应式的,并且可以开箱即用地使用RxJava。
1.4 为什么采用响应式Spring
响应式系统非常复杂,在构建这类系统时困难比较多。要轻松创建响应式系统,就必须首先分析能够构建这类系统的框架,然后选择其中一个。选择框架最常用的方法之一是分析其可用功能、相关性以及社区。
在 JVM 领域,构建响应式系统的最知名框架是 Akka 和 Vert.x 生态系统。
Spring 框架使用适合开发人员的编程模型,为构建 Web 应用程序提供了广泛的可能性。
2.无处不在在响应性
2.1 api不一致问题
大量的同类型响应式库可供选择(如RxJava,CompletableStage,Vert.x,AKKA等)。
我们可能依赖于使用 RxJava 的 API 来编写正在处理的数据项的流程。要构建一个简单的异步请求−响应交互,依赖 CompletableStage 就足够了。
我们也可以使用特定于框架的类(如org.springframework.util.concurrent.ListenableFuture )来构建组件之间的异步交互,并基于该框架简化开发工作。
Spring 5.x 框架扩展了 ListenableFuture 的 API 并且提供了一个 Completable 的方法来解决不兼容的问题
但根本问题还在于没有标准
2.2 推拉
在整个响应式环境演变的早期阶段,所有库的设计思想都是把数据从源头推送到订阅者。因为纯粹的拉模型在某些场景下效率不够高。
2.3 流量控制问题
采用推模型主要是因为可以通过将请求量减少到最小以优化整体处理时间
这就是为什么RxJava 1.x及类似的开发库以推送数据为目的进行设计,这也是为什么流技术能成为分布式系统中组件之间重要的通信技术。
如果仅仅与推模型进行组合,那么该技术有其局限性。消息驱动通信的本质是假设每个请求都会有一个响应,因此服务可能收到异步的、潜在的无限消息流。而这里存在陷阱,因为如果生产者不关注消费者的吞吐能力,它可能会以下面两节中描述的方式影响系统的整体稳定性。
- 慢生产者和快消费者
- 快生产者和慢消费者
使用队列处理所推送数据的关键要素之一是选择具有合适特性的队列。
无界队列
最明显的解决方案是提供一个具有无限大小特性的队列,简单地说就是一个无界队列。在这种情况下,所有生成的元素首先存储在队列中,然后由实际订阅者进行消费
一方面,使用无界队列处理消息带来的核心好处是消息的可传递性,这意味着消费者将在某个时间点及时处理所有存储的元素。
另一方面,只要成功实现消息的可传递性,因为没有无限制的资源,应用程序的回弹性就会降低。例如,一旦内存达到上限,整个系统很容易崩溃。
有界丢弃队列
为了避免内存溢出,我们还可以使用在自身已满的情况下可以忽略传入的消息的队列
该技术考虑了资源的限制,并且可以根据资源的能力配置队列的容量。当消息的重要性很低时,采用这种队列是一种常见的做法。
有界阻塞队列
然而,在每个消息都很重要的情况下,上述技术是不可接受的。例如,支付系统必须处理每个用户提交的支付请求,绝不允许丢弃一部分请求。因此,我们可以在达到上限后阻塞生产者,却不能丢弃消息并保留有界队列以处理被推送的数据。具备阻塞生产者能力的队列通常被称为阻塞队列。
遗憾的是,这种技术否定了系统的所有异步行为
通常,纯推模型中不受控制的语义可能导致许多我们不希望出现的情况。这就是为什么响应式规范要提到使系统巧妙地响应负载的机制的重要性,即背压控制机制的重要性。
遗憾的是,类似 RxJava 1.x 这样的响应式库并没有提供这样的标准化功能。没有明确的 API能用于控制开箱即用的背压机制。
2.4 解决方案
2013 年年末,来自 Lightbend、Netflix 和 Pivotal 的一群天才工程师齐聚一堂,共同解决上述问题并为 JVM 社区提供标准。
经过长达一年的努力,响应式流规范的初稿公诸于世。
其概念就是响应式编程模式的标准化。
3.响应式流规范
3.1 响应式流规范基础
响应式规范发布了一组接口,用于实现
<dependency>
<groupId>org.reactivestreams</groupId>
<artifactId>reactive-streams</artifactId>
<version>1.0.3</version>
</dependency>
<dependency>
<groupId>org.reactivestreams</groupId>
<artifactId>reactive-streams-tck</artifactId>
<version>1.0.3</version>
</dependency>
<dependency>
<groupId>org.reactivestreams</groupId>
<artifactId>reactive-streams-tck-flow</artifactId>
<version>1.0.3</version>
</dependency>
<dependency>
<groupId>org.reactivestreams</groupId>
<artifactId>reactive-streams-examples</artifactId>
<version>1.0.3</version>
</dependency>
规范:
响应式流(Reactive Streams)规范,规定了异步组件之间使用背压进行交互。
响应式流在Java 9中使用Flow API适配。Flow API是互操作的规范,而不是具体的实现,它的语义跟响应式流规范一致。
接口:
Publisher
表示数据流的生产者或数据源,包含一个方法让订阅者注册到发布者,Publisher 代表了发布者和订阅者直接连接的标准化入口点。
public interface Publisher<T> { public void subscribe(Subscriber<? super T> s); }Subscriber
表示消费者,onSubscribe 方法为我们提供了一种标准化的方式来通知 Subscriber 订阅成功。
public interface Subscriber<T> { //发布者在开始处理之前调用,并向订阅者传递一个订阅票据对象 public void onSubscribe(Subscription s); //用于通知订阅者发布者发布了新的数据项。 public void onNext(T t); //用于通知订阅者,发布者遇到了异常,不再发布数据事件。 public void onError(Throwable t); //用于通知订阅者所有的数据事件都已发布完。 public void onComplete(); }Subscription
同时,onSubscribe 方法的传入参数引入一个名为 Subscription(订阅)的订阅票据。Subscription 为控制元素的生产提供了基础。
public interface Subscription { //用于让订阅者通知发布者随后需要发布的元素数量 public void request(long n); //用于让订阅者取消发布者随后的事件流。 public void cancel(); }Processor
如果实体需要转换进来的项目,并将转换后的项目传递给另一个订阅者,此时需要Processor接口。该接口既是订阅者,又是发布者
public interface Processor<T, R> extends Subscriber<T>, Publisher<R> { }
Publisher 保证只有在 Subscriber 要求时才发送元素中新的部分。
Publisher 的整体实现既可以采用纯粹的阻塞等待,也可以采用仅在 Subscriber 请求下才生成数据的复杂机制。
该规范为我们提供了混合推拉模型,此模型可以对背压进行合理控制。
另外,在某些情况下,可以优先考虑纯推模型。响应式流非常灵活,除动态推拉模型外,该规范还提供了独立的推模型和拉模型。根据文档,为了实现纯推模型,我们可以考虑请求 263−1(java.lang.Long.MAX_VALUE)个元素的需求。
相反,要切换到纯拉模型,可以在 Subscriber.onNext 方法中请求新元素。
3.2 响应式流规范实战
示例代码:demo-1_3_2
3.3 响应式流技术兼容套件
TCK
响应式流看着比较简单,实际上包含许多隐藏的陷阱。除 Java 接口之外,该规范还包含许多针对实现的文档化规则。这些规则严格限制每个接口,同时,保留规范中提到的所有行为至关重要。
开发人员需要一个可以验证所有行为并确保响应式库标准化且相互兼容的通用工具
Konrad Malawski 已经为此实现了一个工具包,其名称为响应式流技术兼容套件(ReactiveStreams Technology Compatibility Kit),简称为 TCK。
其实就是写好的测试用例方法包
发布者、订阅者验证见示例代码:demo-1_3_2 test文件夹下
4.响应式流中的异步和并行
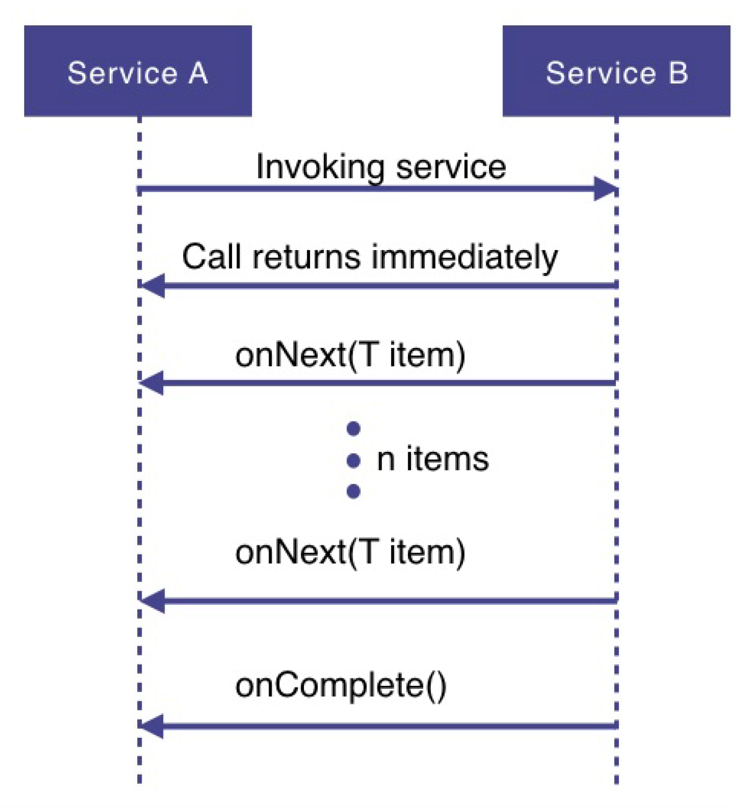
一方面,响应式流 API 中的规则 2.2 和 3.4 规定,对由 Publisher 生成并由 Subscriber消费的所有信号的处理过程应该是非阻塞和非干扰的。因此,基于具体的执行环境,可以高效地利用处理器的一个节点或一个内核。
另一方面,所有处理器或内核的高效利用需要并行化。对响应式流规范中的并行化概念的通常理解可以解释为对 Subscriber#onNext 方法的并行调用。
遗憾的是,规范中的规则 1.3 规定必须以线程安全的方式触发 onXxx 方法的调用,并且如果由多个线程执行,则使用外部同步。这一点假定对所有 onXxx 方法的串行化或简单顺序调用。反过来,这意味着无法创建类似ParallelPublisher 的组件并在流中对元素执行并行处理。
因此,问题是如何高效地利用资源。要找到答案,必须分析常见的流处理管道,见下图:
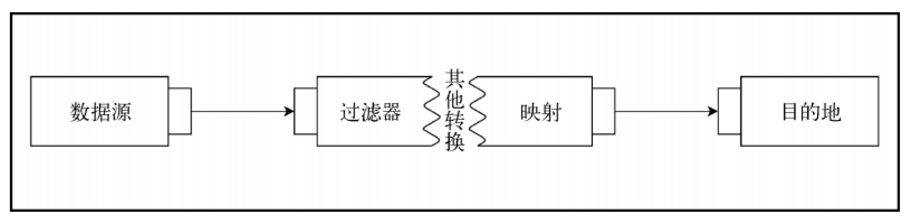
通常的管道处理(涉及数据源和最终目的地)包括一些处理或转换阶段。同时,每个处理阶段可能花费大量处理时间并延迟其他执行。
一种解决方案是在阶段之间传递异步消息。对基于内存的流处理而言,这意味着执行过程的一部分被绑定到一个线程而另一部分被绑定到另一个线程。
例如,最终元素消费可能是 CPU 密集型任务,而它将在单独的线程上进行合理处理,见下图:
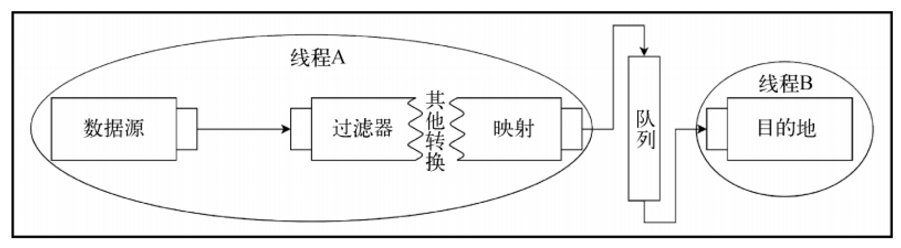
通常的做法是:在两个独立的线程之间拆分处理过程,在阶段之间放置异步边界。
又因为两个线程可以彼此独立地工作,所以通过这样做,将元素的整体处理过程并行化。为了实现并行化,必须应用一种数据结构(例如 Queue)来正确地解耦处理过程。
这样,线程 A 内的处理过程独立地提供数据项给 Queue,而在线程 B 内的 Subscriber 则独立地消费来自相同Queue 的数据项。
三个简单的选项:
- 将处理流附加到数据源资源,并且使所有操作都在与数据源相同的边界内执行。数据源这一侧的边界内,数据通过管道流式处理。
- 处理过程连接到目的地或消费者线程,可以在元素生产过程为 CPU 密集型任务的场景下使用。
- 发生在生产和消费是 CPU 密集型任务时。因此,在单独的线程对象上运行它,见下图
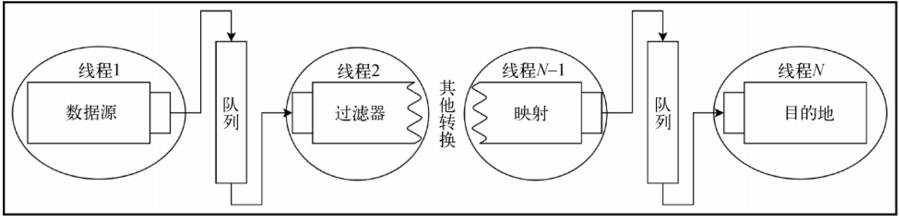
每个处理阶段可以绑定到一个单独的线程。
5.响应式环境的转变
5.1 RxJava的转变
RxJava 提供了一个额外的模块,可以轻松地将一种响应式类型转换为另一种。
RxJava 的开发人员关心我们并提供了一个额外的 RxReactiveStreams 类,使我们可以将 Observable 转换为响应式流中的 Publisher。此外,随着响应式流规范的出现,RxJava 开发人员还提供了非标准化的背压支持,以使转换后的 Observable 兼容响应式流规范。
Dávid Karnok 是RxJava的第 2 版之父,他显著改进了整个库的设计,并引入了符合响应式流规范的其他类型。虽然由于向后兼容性,Observable继续维持不变,但同时,RxJava 2 提供了名为 Flowable的新响应式类型。
5.2 Vert.x的调整
随着 RxJava 的转变,其他响应式库和框架提供商也开始采用响应式流规范。为了遵循规范,Vert.x包含一个额外的模块,该模块为响应式流 API 提供支持。
5.3 Ratpack的改进
除了 Vert.x,另一个名为 Ratpack 的著名 Web 框架也提供对响应式流的支持。与 Vert.x 相比,Ratpack 提供了对响应式流的直接支持。
6.Spring响应式编程
6.1 Spring 的早期响应式解决方案
Spring 4.x 引入了 ListenableFuture 类,它扩展了 Java Future,并且可以基于 HTTP 请求实现异步执行操作。但是只有少数 Spring 4.x 组件支持新的 Java 8 CompletableFuture,后者引入了一些用于组合异步执行的简洁方法。
观察者模式
好像观察者模式似乎与响应式编程无关。但是,经过一些小修改,它定义了响应式编程的基础。
观察者模式拥有一个主题(subject),其中包含该模式的依赖者列表,这些依赖者被称为观察者(Observer)。
见示例代码:demo-1_6_1-1
基于@EventListener注解的发布和订阅模式
Spring 的@EventListener 注解实现事件分发,ApplicationEventPublisher 类实现事件发布。
@EventListener 和 ApplicationEventPublisher 实现了发布−订阅模式(Publish-Subscribepattern),它可以被视为观察者模式的变体。
发布−订阅模式在发布者和订阅者之间提供了额外的间接层。
@EventListener 注解支持基于主题和基于内容的路由。消息类型作为主题的角色;condition 属性基于内容进行事件的路由,事件路由处理基于 Spring 表达式语言(SpEL)。
使用@EventListener注解构建应用程序
见示例代码:demo-1_6_1-2
6.2 使用RxJava作为响应式框架
ReactiveX 通常被定义为观察者模式、迭代器模式和函数式编程的组合。
Java平台上有一个用于响应式编程的标准库,即RxJava,是 Reactive Extensions(响应式扩展,也称为 ReactiveX)的 Java 实现。目前,它不是唯一的响应式库,还有Akka Streams和Project Reactor。
此外,随着 2.x版的发布,RxJava本身发生了很大的变化。
目前最新版本是RxJava3。
RxJava 是迄今为止应用最广泛的响应式库。
6.2.1 响应式流
观察者模式为我们提供了一张清晰分离的生产者(Producer)事件和消费者(Consumer)事件视图,1_6_1-1
如果不希望生产者在消费者出现之前生成事件,则可以使用迭代器(Iterator)模式。如下代码:
public interface Iterator<E> {
boolean hasNext();
E next();
}
将迭代器模式和观察者模式相结合,如下代码
public interface RxObserver<T> {
void onNext(T next);
void onComplete();
void onError(Exception e);
}
虽然 RxObserver 非常类似于 Iterator,但它:
- 不是调用 Iterator 的 next()方法,而是通过 onNext()回调将一个新值通知给 RxObserver。
- 不是检查 hasNext()方法的结果是否为true ,而是通过调用 onComplete()方法通知RxObserver 流的结束。
- onError处理错误
则刚刚设计了一个 Observer 接口,这是 RxJava 的基本概念。
Observable 响应式类是观察者模式中 Subject 的对应类。Observable 扮演事件源的角色,它会发出元素。它有数百种流转换方法以及几十种初始化响应式流的工厂方法。
Subscriber 抽象类不仅实现 Observer 接口并消费元素,还被用作 Subscriber 的实际实现的基础。
Observable 和 Subscriber 之间的运行时关系由 Subscription 控制,Subscription 可以检查订阅状态并在必要时取消订阅。如下图所示:
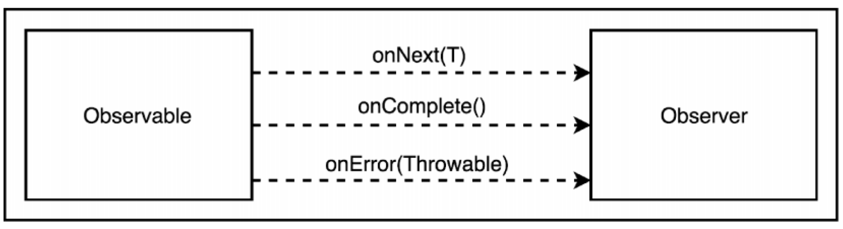
RxJava 定义了有关发送元素的规则,使 Observable 能发送任意数量的元素(包括零个)。然后它通过声明成功或引发错误来指示执行结束。
Observable 会为订阅它的每个Subscriber 多次调用 onNext(),然后再调用 onComplete()或onError()(但不能同时调用两者)。所以在 onComplete()或 onError()之后调用 onNext()是不可行的。
6.2.2 生产和消费数据
见代码:demo-1_6_2-1
- 普通生产消费
- Observable.just
- Observable.from
- Observable.concat
6.2.3 生成异常步序列
RxJava 不仅可以生成一个未来的事件,还可以基于时间间隔等生成一个异步事件序列
Subscription可以控制观察者−订阅者协作
public interface Subscription {
// 订阅取消
void unsubscribe();
// 检查 Subscriber是否仍在等待事件
boolean isUnsubscribed();
}
示例代码:demo-1_6_2-2
6.2.4 操作符
响应式编程包含一个 Observable 流、一个 Subscriber,以及订阅票据 Subscription。
该 Subscription 会传达 Subscriber 从 Observable 生产者处接收事件的意图
RxJava 为几乎所有可能的场景提供了大量的操作符,但是多数其他操作符只是这些基本操作符的组合。
示例代码见:demo-1_6_2-3
map操作符
public final <R> Observable<R> map(Func1<? super T, 1 ? extends R> func)func 函数可以将 T 对象类型转换为 R 对象类型,并且应用 map 将Observable
转换为Observable 。 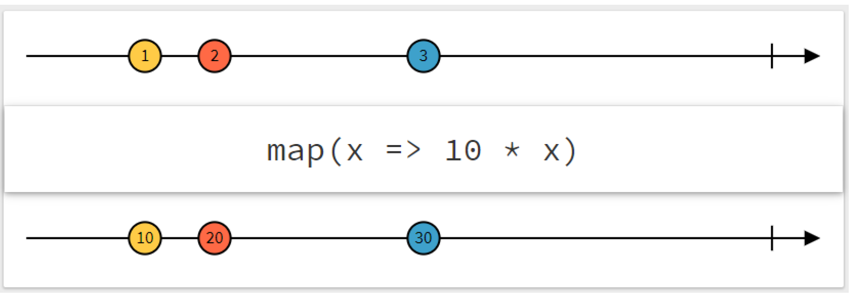
filter操作符
与 map 操作符相比,filter 操作符所产生的元素可能少于它所接收的元素
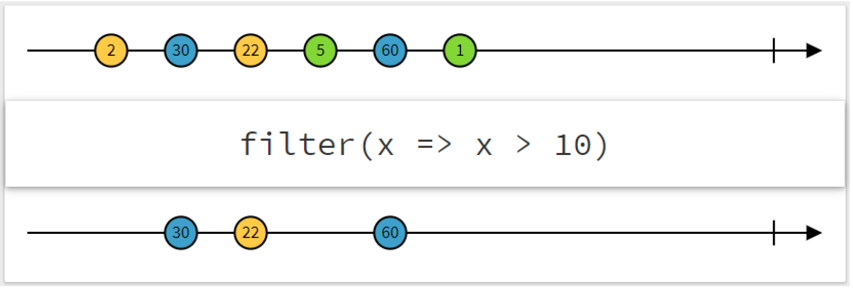
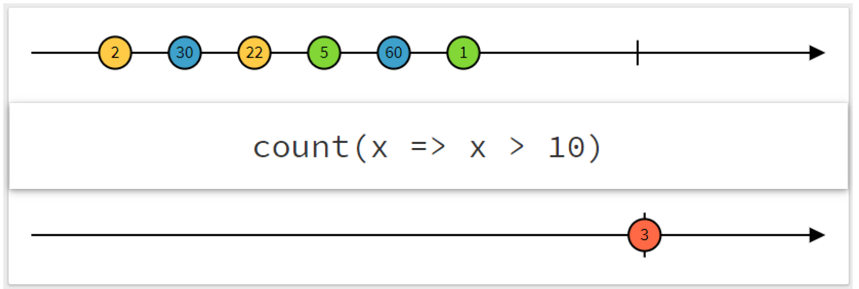
count操作符
count 操作符自描述性很强,它发出的唯一值代表输入流中的元素数量。但是,count 操作符只在原始流结束时发出结果,因此,在处理无限流时,count 操作符将不会完成或返回任何内容
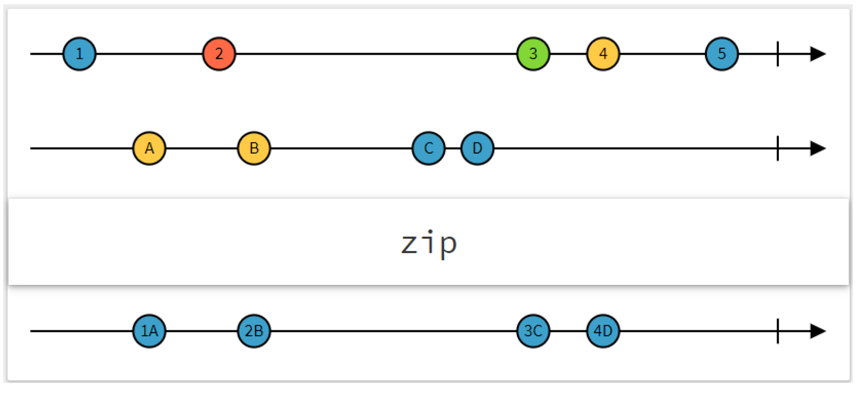
zip操作符
该操作符具有更复杂的行为,因为它会通过应用 zip函数来组合来自两个并行流的值。它通常用于填充数据,且特别适用于部分预期结果从不同源获取的情况
6.2.5 RxJava的先决条件和优势
在生产者和订阅者之间通常存在一些订阅信息,这些信息使打破生产者−消费者关系成为可能。
这种方式非常灵活,并使我们可以控制生产和消费的事件数量,节省 CPU 时间(CPU 时间通常会浪费在创建永远不会用到的数据上)。
为了证明响应式编程提供了节省资源的能力,请假设我们需要实现一个简单的内存搜索引擎服务。该服务应该返回一个 URL 集合,其中的 URL 链接到包含了所需短语的文档。通常,客户端应用程序(Web 或移动应用程序)也会传入一些限制条件,例如有效结果的最大返回量。
如果没有响应式编程,我们可能使用以下 API 设计此类服务
public interface SearchEngine { /** * 将查询结果限定为limit条,返回结果 * @param query * @param limit * @return */ List<URL> search(String query, int limit); }此时,即使有人在客户端结果界面只选择了第一个或第二个结果,服务的客户端也会收到整个结果集。
在这种情况下,虽然我们的服务做了很多工作,客户端也已经等了很长时间,客户端却忽略了大部分结果。这无疑是一种资源浪费
我们可以通过遍历结果集来对搜索结果进行处理
因此,只要客户端继续消费它们,服务器就会搜索下一个结果项。通常,服务器的搜索过程不是针对每一行,而是针对某些固定大小(比方说 100 项)。在客户端,结果以迭代器的形式表示。
public interface IterableSearchEngine { /** * @param query * @param limit * @return */ Iterable<URL> search(String query, int limit); }迭代器的唯一缺点是,客户端的线程在主动等待新的数据时会产生阻塞。该交互方式效率不高,不足以构建高性能应用程序。
搜索引擎可以返回 CompletableFuture 以构建异步服务
此时,客户端线程可以做一些有用的事情,而不会搅乱搜索请求,因为服务会在结果到达时立即执行回调。
但是在这里我们同样要么收到全部结果,要么收不到结果,因为 CompletableFuture 只能包含一个值,即使所包含的值是一个结果列表,也是如此。
public interface FutureSearchEngine { /** * 搜索 * @param query * @param limit * @return */ CompletableFuture<List<URL>> search(String query, int limit); }通过使用 RxJava,返回一个流
同时客户端可以随时取消订阅(即unsubscribe()),减少搜索服务处理过程中所需完成的工作量
public interface RxSearchEngine { /** * 搜索 * @param query * @return */ Observable<URL> search(String query); }RxJava 使以更加通用和灵活的方式异步组合数据流成为可能。也可以将旧式同步代码包装到异步工作流中。
6.2.6 Rxjava的使用
示例代码:demo-1_6_2-4
6.3 Spring响应式编程的实现
Spring webflux
Spring Framework 5添加新模块spring-web-reactive ,使用响应式非阻塞引擎支持类似SpringMVC的@Controller编程模型。
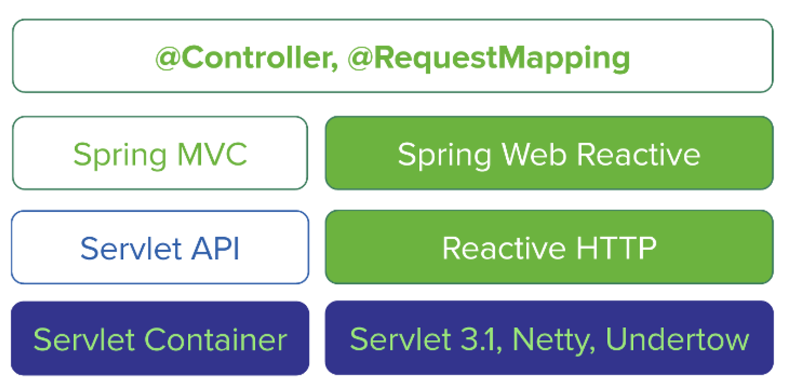
Spring Web Reactive使用Servlet 3.1非阻塞特性。也可以运行于非Servlet运行时,如Netty和Undertow等
对每个运行时适配了一组公共的响应式
ServerHttpRequest和ServerHttpResponse抽象,以Flux<DataBuffer>的形式暴露请求和响应,读写完全支持背压。spring-core 模块提供了Encoder 和Decoder 契约,用于对Flux 的数据进行序列化和反序列化。
spring-web 模块添加了JSON和XML的实现,用于web应用或其他的SSE流和零拷贝文件传输。
spring-web-reactive 模块包含了Spring Web Reactive框架以支持@Controller编程模型。
重新定义了很多Spring MVC的契约,如HandlerMapping 和HandlerAdapter 以支持异步和非阻塞,响应式地操作HTTP的请求和响应。
下述类型都可以作为控制器方法的@RequestBody参数来使用:
Account account — account在调用控制器之前非阻塞地反序列化。
Mono
account —控制器使用Mono 声明执行的逻辑,当account反序列化之后执行。 Single
account — 跟Mono 一样,但是使用RxJava执行引擎。 Flux
accounts — 输入流场景 Observable
accounts — 使用RxJava的输入流
返回值类型
Mono
— 当Mono结束,非阻塞地序列化给定的Account对象 Singe
— 跟Mono的一样,但是使用RxJava执行引擎。 Flux
— 流场景,根据请求content type的不同,有可能是SSE。 Flux
— SSE 流。 Observable
— 使用RxJava执行引擎的SSE流。 Mono
— 当Mono结束,请求处理结束。 void — 当方法返回,请求处理结束。表示同步、非阻塞的控制器方法。
Account — 非阻塞地序列化给定的Account,表示同步、非阻塞控制器方法。
WebSocket
最知名的全双工客户端−服务器通信双工协议,即WebSocket。
WebSocket 协议的通信于2013 年初引入到Spring 框架中,旨在进行异步消息发送,但其实际的实现仍然有一些阻塞操作。
例如,将数据写入I/O 或从I/O 读取数据仍然是阻塞操作,因此这二者都会影响应用程序的性能。
WebFlux 模块为WebSocket 引入了改进版本的基础设施。WebFlux 同时提供客户端和服务器基础设施。
服务器端 websocket api
WebFlux 提供WebSocketHandler 作为处理WebSocket 连接的核心接口
class EchoWebSocketHandler implements WebSocketHandler { //WebSocketSession 类表示客户端和服务器之间的成功握手,并提供对包括有关握手、会话属性和传入数据流的信息的访问 @Override public Mono<Void> handle(WebSocketSession session) { return session.receive() .map(WebSocketMessage::getPayloadAsText) .map(tm -> "Echo: " + tm) .map(session::textMessage) .as(session::send); } } //上述代码表示接收入站消息,并转换,然后封装为WebSocketMessage对象,发送出去。其中发送返回Mono<Void>,当写出完成,该Mono完成。 //WebSocketMessage 是DataBuffer 的包装器,它提供了额外功能,例如将以字节为单位的有效负载转换为文本。 //一旦提取了传入消息,我们在该文本前面加上“Echo:”后缀,将新文本消息包装在WebSocketMessage 中,并使用WebSocketSession#send 方法将其发送回客户端。这里,send 方法接受Publisher<WebSocketMessage>并返回Mono<Void>作为结果。 //因此,通过使用Reactor API 中的as 操作符,我们可以将Flux 视为Mono<Void>,并使用session::send 作为转换函数。除了WebSocketHandler 接口实现,设置服务器端WebSocket API 还需要配置其他HandlerMapping 实例和WebSocketHandlerAdapter 实例。
@Configuration public class WebSocketConfiguration { @Bean public HandlerMapping handlerMapping() { SimpleUrlHandlerMapping mapping = new SimpleUrlHandlerMapping(); mapping.setUrlMap(Collections.singletonMap("/ws/echo", new EchoWebSocketHandler())); // 为了在其他HandlerMapping实例之前处理SimpleUrlHandlerMapping,它应该具有更高的优先级 mapping.setOrder(-1); return mapping; } @Bean public HandlerAdapter handlerAdapter() { // 将HTTP 连接升级到WebSocket,然后调用了WebSocketHandler#handle 方法 return new WebSocketHandlerAdapter(); } }客户端WebSocket API
与WebSocket 模块(基于Web MVC)不同,WebFlux 还为我们提供了客户端支持。要发送WebSocket 连接请求,可以使用WebSocketClient 类。
public interface WebSocketClient { Mono<Void> execute( URI url, WebSocketHandler handler ); Mono<Void> execute( URI url, HttpHeaders headers, WebSocketHandler handler ); }WebSocketClient 使用相同的WebSockeHandler 接口来处理来自服务器的消息并发回消息。有一些WebSocketClient 实现与服务器引擎相关,例如
TomcatWebSocketClient实现或JettyWebSocketClient实现。/** * 需要添加VM选项: * --add-opens java.base/jdk.internal.misc=ALL-UNNAMED * -Dio.netty.tryReflectionSetAccessible=true * --illegal-access=warn * @param args * @throws InterruptedException */ public static void main(String[] args) throws InterruptedException { WebSocketClient client = new ReactorNettyWebSocketClient(); client.execute(URI.create("http://localhost:8080/ws/echo"), session -> { session.receive() .map(WebSocketMessage::getPayloadAsText) .subscribe(System.out::println); return Flux.interval(Duration.ofMillis(500)) .map(String::valueOf) .map(session::textMessage) .as(session::send); } ).subscribe(); Thread.sleep(5000); }Spring WebSocket 模块的主要缺点是它阻塞了与I/O的交互,而Spring WebFlux 提供了完全无阻塞的写入和读取。
WebFlux 模块通过使用响应式流规范和Project Reactor 提供了更好的流抽象。旧WebSocket 模块中的WebSocketHandler 接口只允许一次处理一条消息。此外,WebSocketSession#sendMessage 方法仅允许以同步方式发送消息。
旧Spring WebSocket 模块的一个关键特性就是它与Spring Messaging 模块的良好集成,而这能用@MessageMapping 注解来声明WebSocket 端点。
以下代码展示了旧WebSocket API 的简单示例,这些API 基于Web MVC,且使用SpringMessaging 中的注解:
@Controller public class GreetingController { @MessageMapping("/hello") @SendTo("/topic/greetings") public Greeting greeting(HelloMessage message) { return new Greeting("Hello, " + message.getName() + "!"); } }
作为WebSocket轻量级替代品的响应式SSE
与重量级WebSocket 一起,HTML5 引入了一种创建静态(在本例中为半双工)连接的新方法,其中服务器能够推送事件。该技术解决了与WebSocket 类似的问题。
例如,可以使用相同的基于注解的编程模型声明服务器发送事件(Server-Sent Events,SSE)流,但是返回一个无限的ServerSentEvent 对象流,如以下示例所示:
@RestController @RequestMapping("/sse/stocks") class StocksController { final Map<String, StocksService> stocksServiceMap; ... @GetMapping public Flux<ServerSentEvent<?>> streamStocks() { return Flux .fromIterable(stocksServiceMap.values()) .flatMap(StocksService::stream) .<ServerSentEvent<?>>map(item -> ServerSentEvent .builder(item) .event("StockItem") .id(item.getId()) .build() ) .startWith( ServerSentEvent .builder() .event("Stocks") .data(stocksServiceMap.keySet()) .build() ); } }这种情况下,WebFlux 框架在内部将流的每个元素包装到ServerSentEvent 中。
正如上述示例所示,ServerSentEvent 技术的核心优势在于这种流模型的配置不需要额外的样板代码,而在WebFlux 中采用WebSocket 时则需要这些样板代码。这是因为SSE 是一种基于HTTP 的简单抽象,既不需要协议切换,也不需要特定的服务器配置。如上述示例所示,我们可以使用@RestController和@XXXMapping 注解的传统组合来配置SSE。但是,对于WebSocket而言,我们需要自定义消息转换配置,例如手动选择特定的消息传递协议。相比之下,Spring WebFlux 为SSE 提供的消息转换器配置与为典型REST 控制器提供的相同。
另外,SSE 不支持二进制编码并将事件限制为UTF-8 编码。这意味着WebSocket 可能对较小的消息有用,并且在客户端和服务器之间传输的流量较少,因此具有较低的延迟。
总而言之,SSE 通常是WebSocket 的一个很好的替代品。由于SSE 是HTTP 协议的抽象,因此WebFlux 支持与典型REST 控制器相同的声明性函数式端点配置和消息转换。
RSocket
RSocket是一个应用通信协议,用在多路复用全双工通信中。可以在TCP、WebSocket或其他字节流传输中使用。提供了如下交互模型:
- Request-Response — 发送一个消息,接收一个消息
- Request-Stream — 发送一个消息,接收返回的消息流
- Channel — 双向发送消息流
- Fire-and-Forget — 发送单向消息
建立初始连接之后,就没有客户端服务端的概念了,因为双方地位对称,都可以初始化交互。因此,RSocket中只有请求者和响应者,而没有客户端和服务端的概念,交互称为“请求流”或简单地称为“请求们”。
RSocket协议的关键特性和优势:
- 跨网络边界的响应式流语义 — 对于诸如“请求流”和“通道”之类的流请求,背压信号在请求者和响应者之间传播,从而允许请求者放慢源处的响应者的速度,从而减少了对网络层拥塞控制的依赖以及在网络级别或任何级别缓冲。
- Request throttling — 可以从两端发送的“ LEASE”帧,因此命名为“ Leasing”,以限制给定时间内另一端允许的请求总数。 租约定期更新。
- Session恢复 — 这是专为断开连接而设计的,用于维护会话的状态。 状态管理对于应用程序是透明的,并且可以与背压结合使用,从而可以在可能的情况下停止生产者并减少所需的状态量。
- 对大消息的分割和再组装。
- Keepalive(心跳)
建立连接
最初,客户端通过一些低级流传输(例如TCP或WebSocket)连接到服务器,并向服务器发送“SETUP”帧以设置连接参数。
服务器可以拒绝“ SETUP”帧,但是通常在发送(对于客户端)和接收(对于服务器)之后,双方都可以开始发出请求,除非“ SETUP”指示使用租赁语义来限制数量。在这种情况下,双方都必须等待另一端的“租约”帧以允许发出请求。
发起请求
一旦建立连接,双方就可以通过帧“ REQUEST_RESPONSE”,“ REQUEST_STREAM”,“REQUEST_CHANNEL”或“ REQUEST_FNF”之一发起请求。 这些帧中的每一个都将一个消息从请求者传送到响应者。
响应者然后可以返回带有响应消息的“ PAYLOAD”帧,并且在“ REQUEST_CHANNEL”的情况下,请求者还可以发送带有更多请求消息的“ PAYLOAD”帧。
当请求涉及诸如“请求流”和“通道”之类的消息流时,响应者必须遵守来自请求者的需求信号。 需求表示为许多消息。 初始需求在“ REQUEST_STREAM”和“ REQUEST_CHANNEL”框架中指定。 随后的需求通过“ REQUEST_N”帧发出信号。
每一端还可以通过“ METADATA_PUSH”帧发送元数据通知,该元数据通知与任何单独的请求无关,而与整个连接有关。
消息格式
RSocket消息包含数据和元数据。 元数据可用于发送路由,安全令牌等。数据和元数据的格式可以不同。 每个类的Mime类型都在“ SETUP”框架中声明,并应用于给定连接上的所有请求。
尽管所有消息都可以具有元数据,但通常每个请求都包含诸如路由之类的元数据,因此仅包含在请求的第一条消息中,即带有帧“ REQUEST_RESPONSE”,“ REQUEST_STREAM”,“ REQUEST_CHANNEL”或“ REQUEST_FNF”之一 。
RSocket的Java实现基于Project Reactor构建。 TCP和WebSocket的传输建立在Reactor Netty上。作为响应式库,Reactor简化了实现协议的工作。对于应用程序,自然要配合使用带有声明性运算符和透明背压支持的“ Flux”和“ Mono”。
WebClient
Spring Framework 5在RestTemplate 之外添加了新的响应式WebClient 。
每个支持的HTTP客户端适配了一组公共的响应式ClientHttpRequest 和ClientHttpResponse 抽象,以Flux
的形式对外暴露请求和响应,读写完全支持背压 spring-core 提供了Encoder 和Decoder 抽象,用于客户端的Flux字节进行序列化和反序列化
ClientHttpConnector connector = new ReactorClientHttpConnector(); WebClient.builder().clientConnector(connector).build() .get() .uri(URI.create("https://edu.lagou.com")) .accept(MediaType.TEXT_HTML) .retrieve() .bodyToMono(String.class) .subscribe(System.out::println); Thread.sleep(10000);