常⻅问题及解决⽅案
新服务上线后,服务消费者不能访问到刚上线的新服务,需要过⼀段时间后才能访问?或是将服务下线后,服务还是会被调⽤到,⼀段时候后才彻底停⽌服务, 这其实就是服务发现的⼀个问题,当我们需要调⽤服务实例时,信息是从注册中⼼Eureka获取的,然后通过Ribbon选择⼀个服务实例发起调⽤,如果出现调⽤不到或者下线后还可以调⽤的问题,原因肯定是服务实例的信息更新不及时导致的。
Eureka服务发现慢的原因
Eureka服务发现慢的原因主要有两个,⼀部分是因为服务缓存导致的,另⼀部分是因为客户端缓存导致的。
服务端缓存
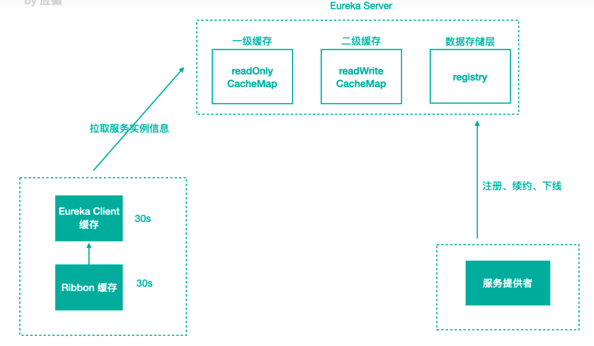
服务注册到注册中⼼后,服务实例信息是存储在注册表中的,也就是内存中。但Eureka为了提⾼响应速度,在内部做了优化,加⼊了两层的缓存结构,将Client需要的实例信息,直接缓存起来,获取的时候直接从缓存中拿数据然后响应给Client。第⼀层缓存是readOnlyCacheMap,readOnlyCacheMap是采⽤ConcurrentHashMap来存储数据的,主要负责定时与readWriteCacheMap进⾏数据同步,默认同步时间为30秒⼀次。
第⼆层缓存是readWriteCacheMap,readWriteCacheMap采⽤Guava来实现缓存。缓存过期时间默认为180秒,当服务下线、过期、注册、状态变更等操作都会清除此缓存中的数据。
Client获取服务实例数据时,会先从⼀级缓存中获取,如果⼀级缓存中不存在,再从⼆级缓存中获取,如果⼆级缓存也不存在,会触发缓存的加载,从存储层拉取数据到缓存中,然后再返回给Client。
Eureka之所以设计⼆级缓存机制,也是为了提⾼EurekaServer的响应速度,缺点是缓存会导致Client获取不到最新的服务实例信息,然后导致⽆法快速发现新的服务和已下线的服务。
了解了服务端的实现后,想要解决这个问题就变得很简单了,我们可以缩短只读缓存的更新时间(
eureka.server.response-cache-update-interval-ms)让服务发现变得更加及时,或者直接将只读缓存关闭(eureka.server.use-read-only- response-cache=false),多级缓存也导致C层⾯(数据⼀致性)很薄弱。EurekaServer中会有定时任务去检测失效的服务,将服务实例信息从注册表中移除,也可以将这个失效检测的时间缩短,这样服务下线后就能够及时从注册表中清除。
EurekaClient缓存
EurekaClient负责跟EurekaServer进⾏交互,在EurekaClient中的
com.netflix.discovery.DiscoveryClient.initScheduledTasks()⽅法中,初始化了⼀个CacheRefreshThread定时任务专⻔⽤来拉取EurekaServer的实例信息到本地。Ribbon缓存
Ribbon会从EurekaClient中获取服务信息,ServerListUpdater是Ribbon中负责服务实例更新的组件,默认的实现是PollingServerListUpdater,通过线程定时去更新实例信息。定时刷新的时间间隔默认是30秒,当服务停⽌或者上线后,这边最快也需要30秒才能将实例信息更新成最新的。我们可以将这个时间调短⼀点,⽐如3秒。
刷新间隔的参数是通过getRefreshIntervalMs⽅法来获取的,⽅法中的逻辑也是从Ribbon的配置中进⾏取值的。
将这些服务端缓存和客户端缓存的时间全部缩短后,跟默认的配置时间相⽐,快了很多。我们通过调整参数的⽅式来尽量加快服务发现的速度,但是还是不能完全解决报错的问题,间隔时间设置为3秒,也还是会有间隔。所以我们⼀般都会开启重试功能,当路由的服务出现问题时,可以重试到另⼀个服务来保证这次请求的成功。
SpringCloud各组件超时
在SpringCloud中,应⽤的组件较多,只要涉及通信,就有可能会发⽣请求超时。那么如何设置超时时间?在SpringCloud中,超时时间只需要重点关注Ribbon和Hystrix即可。
Ribbon
如果采⽤的是服务发现⽅式,就可以通过服务名去进⾏转发,需要配置Ribbon的超时。Rbbon的超时可以配置全局的ribbon.ReadTimeout和ribbon.ConnectTimeout。也可以在前⾯指定服务名,为每个服务单独配置,⽐如user-service.ribbon.ReadTimeout。
Hystrix
其次是Hystrix的超时配置,Hystrix的超时时间要⼤于Ribbon的超时时间,因为Hystrix将请求包装了起来,特别需要注意的是,如果Ribbon开启了重试机制,⽐如重试3次,Ribbon的超时为1秒,那么Hystrix的超时时间应该⼤于3秒,否则就会出现Ribbon还在重试中,⽽Hystrix已经超时的现象。
Hystrix全局超时配置就可以⽤default来代替具体的command名称hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds=3000,如果想对具体的command进⾏配置,那么就需要知道command名称的⽣成规则,才能准确的配置。
如果我们使⽤@HystrixCommand的话,可以⾃定义commandKey。如果使⽤FeignClient的话,可以为FeignClient来指定超时时间:
hystrix.command.UserRemoteClient.execution.isolation.thread.timeoutInMillis econds=3000如果想对FeignClient中的某个接⼝设置单独的超时,可以在FeignClient名称后加上具体的⽅法:
hystrix.command.UserRemoteClient#getUser(Long).execution.isolation.thread.timeoutInMilliseconds=3000Feign
Feign本身也有超时时间的设置,如果此时设置了Ribbon的时间就以Ribbon 的时间为准,如果没设置Ribbon的时间但配置了Feign的时间,就以Feign的时间为准。Feign的时间同样也配置了连接超时时间(feign.client.config.服务名 称.connectTimeout)和读取超时时间(feign.client.config.服务名称.readTimeout)。
建议,我们配置Ribbon超时时间和Hystrix超时时间即可。