Solr配置详解
1. 目录结构说明
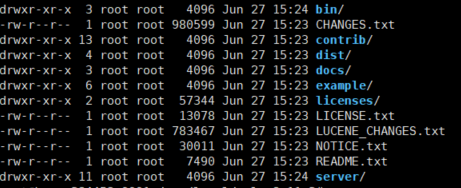
bin: Solr控制台管理工具存在该目录下。如:solr 等。
contrib: 该文件包含大量关于Solr的扩展。
dist: 在这里能找到Solr的核心JAR包和扩展JAR包。当我们试图把Solr嵌入到某个应用程序的时候会用 到核心JAR包。
docs: 该文件夹里面存放的是Solr文档,离线的静态HTML文件,还有API的描述。
example: 包含Solr的简单示例。
licenses: 各种许可和协议。
server: solr应用程序的核心,SolrCore核心必要文件都存放在这里。
#contrib
analysis-extras: 该目录下面包含一些相互依赖的文本分析组件 分词器相关。
clustering: 该目录下有一个用于集群检索结果的引擎。
dataimporthandler: DIH是Solr中一个重要的组件,该组件可以从数据库或者其他数据源导入数据到 Solr中。 dataimporthandler-extras: 这里面包含了对DIH的扩展。
extraction: 集成Apache Tika,用于从普通格式文件中提取文本。
langid: 该组件使得Solr拥有在建索引之前识别和检测文档语言的能力。
prometheus-exporter: 采集监控数据并通过prometheus监控 solr监控相关。 velocity:包含一个基于Velocity: 模板语言简单检索UI框架。
#server
contexts: 启动Solr的Jetty的上下文配置。
etc: Jetty服务器配置文件,在这里可以把默认的8983端口改成其他的。
lib: Jetty服务器程序对应的可执行JAR包和响应的依赖包。
logs: 默认情况下,日志将被输出到这个文件夹。
modules: http\https\server\ssl等配置模块。
resources: 存放着Log4j的配置文件。这里可以改变输出日志的级别和位置等设置。
scripts: Solr运行的必要脚本。
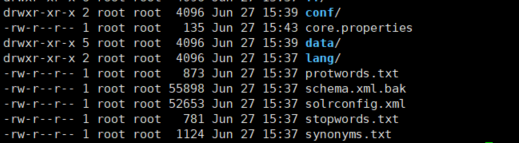
solr: 运行Solr的配置文件都保存在这里。solr.xml文件,zoo.cfg文件,使用SolrCloud的时候有 用。子文件 夹configsets存放着Solr的示例配置文件。每创建一个核心Core都会在server目录下生 成相应的core 名称 目录。 solr-webapp:Solr的平台管理界面的站点就存放在这里。
tmp: 存放临时文件。
2. SolrCore结构
SolrCore内核:是运行在Solr服务器中的具体唯一命名的、可管理和可配置的索引,即内核就是Lucene中说到的索引。一台solr服务器可以托管一个或多个内核
#core.properties
#Written by CorePropertiesLocator
#Mon Jun 27 07:43:33 UTC 2022
name=qiang_core_1
config=solrconfig.xml
schema=schema.xml
dataDir=data
3. solrconfig.xml
这个文件是来配置SolrCore实例的相关信息。如果使用默认配置可以不用做任何修改。它里面包含了很多标签,例如:lib标签、dataDir标签、requestHandler标签等
lib标签
在solrconfifig.xml中可以加载一些扩展的jar,如果需要使用,则首先要把这些jar复制到指定的目录,比
如把安装包中的contrib和dist文件夹, 复制到SolrHome同级目录下 需要把
../../../..修改为../..然后修改solrconfig.xml配置文件中加载扩展的jar路径
dataDir标签
配置SolrCore的data目录.data目录用来存放SolrCore的索引文件和tlog日志文件
<dataDir>${solr.data.dir:}</dataDir>directoryFactory
<directoryFactory name="DirectoryFactory" class="${solr.directoryFactory:solr.NRTCachingDirectoryFactory}"/> 索引存储方案,共有以下存储方案: 1、solr.StandardDirectoryFactory,这是一个基于文件系统存储目录的工厂,它会试图选择最 好的实现基于你当前的操作系统和Java虚拟机版本。 2、solr.SimpleFSDirectoryFactory,适用于小型应用程序,不支持大数据和多线程。 3、solr.NIOFSDirectoryFactory,适用于多线程环境,但是不适用在windows平台(很慢),是因为JVM还存在bug。 4、solr.MMapDirectoryFactory,这个是solr3.1到4.0版本在linux64位系统下默认的实现。它是通过使用虚拟内存和内核特性调用 mmap去访问存储在磁盘中的索引文件。它允许lucene或solr直接访问I/O缓存。如果不需要近实时 搜索功能,使用此工厂是个不错的方案。 5、solr.NRTCachingDirectoryFactory,此工厂设计目的是存储部分索引在内存中,从而加快了 近实时搜索的速度。 6、solr.RAMDirectoryFactory,这是一个内存存储方案,不能持久化存储,在系统重启或服务器 crash时数据会丢失。且不支持索引复制luceneMatchVersion
<luceneMatchVersion>7.7.3</luceneMatchVersion> solr 版本indexConfig
用于设置索引的底层的属性
<!--maxTokenCount即在对某个域分词的时候,最多只提取前10000个Token,后续的域值将被抛弃。--> <filterclass="solr.LimitTokenCountFilterFactory"maxTokenCount="10000"/> <!--writeLockTimeout表示IndexWriter实例在获取写锁的时候最大等待超时时间,超过指定的超时时 间仍未获取到写锁,则IndexWriter写索引操作将会抛出异常。--> <writeLockTimeout>1000</writeLockTimeout> <!--表示创建索引的最大线程数,默认是开辟8个线程来创建索引。--> <maxIndexingThreads>8</maxIndexingThreads>// <useCompoundFile>false</useCompoundFile>//solr默认为false。如果为true,索引文件减少, 检索性能降低,追求平衡。 <!--表示创建索引时内存缓存大小,单位是MB,默认最大是100M 。--> <ramBufferSizeMB>100</ramBufferSizeMB> <!--表示在document写入到硬盘之前,缓存的document最大个数,超过这个最大值会触发索引的flush 操作。--> <maxBufferedDocs>1000</maxBufferedDocs> <mergePolicyclass="org.apache.lucene.index.TieredMergePolicy"> <intname="maxMergeAtOnce">10</int> <intname="segmentsPerTier">10</int> </mergePolicy> //合并策略。 <mergeFactor>10</mergeFactor>//合并因子,每次合并多少个segments。 <mergeSchedulerclass="org.apache.lucene.index.ConcurrentMergeScheduler"/>//合并调度器。 <lockType>${solr.lock.type:native}</lockType>//锁工厂。 <unlockOnStartup>false</unlockOnStartup>//是否启动时先解锁。 <termIndexInterval>128</termIndexInterval>//Luceneloads terms into memory 间隔 <reopenReaders>true</reopenReaders>//重新打开,替代先关闭-再打开。 <deletionPolicyclass="solr.SolrDeletionPolicy"> //提交删除策略,必须实现org.apache.lucene.index.IndexDeletionPolicy <strname="maxCommitsToKeep">1</str> <strname="maxOptimizedCommitsToKeep">0</str> <strname="maxCommitAge">30MINUTES</str> OR <strname="maxCommitAge">1DAY</str> <br> <infoStream file="INFOSTREAM.txt">false</infoStream>//相当于把创建索引时的日志输 出。<lockType>${solr.lock.type:native}</lockType>updateHandler
<updateHandler> <!-- 启用事务日志,用于实时获取,持久化和Solr云副本恢复。日志能够随着未提交的索引增 大而增大,因此推荐使用一个确切的 autoCommit --> <updateLog> <str name="dir">${solr.ulog.dir:}</str> <int name="numVersionBuckets">${solr.ulog.numVersionBuckets:65536}</int> </updateLog> <!-- AutoCommit 满足某种条件时进行提交。 maxDocs - 触发新的提交前的最大document数量. maxTime - 触发新的提交前的最长时间(ms) openSearcher-为false时,提交会使最近索引的变化保存下来。但是这些变化对新的 searcher不可见 如果启用 updateLog,则强烈建议使用某种autoCommit,以限制日志大小。 --> <autoCommit> <maxTime>${solr.autoCommit.maxTime:15000}</maxTime> <openSearcher>false</openSearcher> </autoCommit> <!-- softAutoCommit 与 autoCommit 类似,但是只保证改变可见,不保证改变同步到硬盘。 比hard commit 更快,更接近实时搜索 --> <autoSoftCommit> <!--5秒执行一次软提交--> <maxTime>5000</maxTime> </autoSoftCommit> </updateHandler> 其中硬提交是提交数据持久化到磁盘里面,并且能够查询到这条数据。 软提交是提交数据到内存里面,并没有持久化到磁盘,但是他会把提交的记录写到tlog的日志文件里面query
<query> <!--设置boolean 查询中,最大条件数。在范围搜索或者前缀搜索时,会产生大量的 boolean 条 件,如果条件数达到这个数值时,将抛出异常,限制这个条件数,可以防止条件过多查询等待时间过长。--> <maxBooleanClauses>1024</maxBooleanClauses> <!-- Solr内部查询缓存 有两种缓存实现: LRUCache - 基于同步的 LinkedHashMap (LRU Least Recently Used) FastLRUCache - 基于 ConcurrentHashMap. 在单线程中,FastLRUCache 具有较快的 gets,较慢的 puts。因此当缓存命中率 比较高时(>75%), 会比 LRUCache 更快;并且在多CPU环境下也会更快一点--> <!-- Filter Cache 用于缓存未排序的 SolrIndexSearcher 的查询结果集, 当打开一个新的 searcher 时,可能会使用旧的 searcher 中缓存的值 Parameters: class - SolrCache实现类 (LRUCache or FastLRUCache) size - 缓存中的最大实体数 initialSize - 初始容量 (实体数) autowarmCount - 从旧的缓存中导入的预加载的实体数 --> <filterCache class="solr.FastLRUCache" size="512" initialSize="512" autowarmCount="0"/> <!-- Query Result Cache 缓存排序后的查询结果 maxRamMB - 最大缓存容量 --> <queryResultCache class="solr.LRUCache" size="512" initialSize="512" autowarmCount="0"/> <!-- Document Cache 缓存文档对象 Since Lucene internal document ids are transient, this cache will not be autowarmed. --> <documentCache class="solr.LRUCache" size="512" initialSize="512" autowarmCount="0"/> <!-- 是否能使用到filtercache关键配置 --> <useFilterForSortedQuery>true</useFilterForSortedQuery> <!-- queryresult的结果集控制 --> <queryResultWindowSize>50</queryResultWindowSize> <!-- 是否启用懒加载field --> <enableLazyFieldLoading>false</enableLazyFieldLoading> </query>requestHandler
requestHandler请求处理器,定义了索引和搜索的访问方式
通过/update维护索引,可以完成索引的添加、修改、删除操作
<requestHandler name="/update/extract" startup="lazy" class="solr.extraction.ExtractingRequestHandler" > <lst name="defaults"> <str name="lowernames">true</str> <str name="fmap.meta">ignored_</str> <str name="fmap.content">_text_</str> </lst> </requestHandler>设置搜索参数完成搜索,搜索参数也可以设置一些默认值,如下:
<requestHandler name="/select" class="solr.SearchHandler"> <!-- 默认的查询参数,可被请求中的参数覆盖 --> <lst name="defaults"> <str name="echoParams">explicit</str> <int name="rows">10</int> <!--以指示分布式查询在可用时应首选分片的本地副本。如果查询包含 preferLocalShards=true, 那么查询控制器将查找本地副本来为查询服务,而不是从整个集群中随机选择副本。--> <bool name="preferLocalShards">false</bool> </lst> </requestHandler> <!-- 返回格式化过的(字符串有--> <requestHandler name="/query" class="solr.SearchHandler"> <lst name="defaults"> <str name="echoParams">explicit</str> <str name="wt">json</str> <str name="indent">true</str> <str name="df">text</str> </lst> </requestHandler>
4. schema.xml
Schema:模式,是内核中字段的定义,让solr知道内核包含哪些字段、字段的数据类型、字段对应的索引存储
Solr中提供了两种方式来配置schema,两者只能选其一
- 默认方式,通过Schema API 来实时配置,模式信息存储在内核目录的conf/managed-schema 文件中,一般使用这种方式,特别是在SolrCloud模式下。
- 传统的手工编辑内核 schema.xml的方式,编辑完后需重载集合/内核才会生效。
两种方式之间是可以切换的,比如用于升级操作,从旧版本到新版本的升级,切换方式如下:
手动编辑切换到API方式: 只需将solrconfig.xml中的<schemaFactory class="ClassicIndexSchemaFactory"/>去掉,或改为ManagedIndexSchemaFactory。Solr重启 时,它发现之前存储在schema.xml中但没有存储在 managed-schema中,则它会备份schema.xml,然 后改写schema.xml为managed-schema。此后就可以通过Schema API 管理schema了
API切换到手动编辑方式: 首先将managed-schema重命名为schema.xml;然后将solrconfig.xml中 schemaFactory 的ManagedIndexSchemaFactory去掉(如果存在)或者改为 ClassicIndexSchemaFactory
managed-schema
Solr启动一个服务器实例后,会内置了很多fifield字段、唯一ID、fifieldType字段类型等,这些信息都是在managed-schema文件中定义的。我们先了解下managed-schema文件的大致结构:
<?xml version="1.0" encoding="UTF-8" ?> <schema version="1.6"> <field .../> <dynamicField .../> <uniqueKey>id</uniqueKey> <copyField .../> <fieldType ...> <analyzer type="index"> <tokenizer .../> <filter ... /> </analyzer> <analyzer type="query"> <tokenizer.../> <filter ... /> </analyzer> </fieldType> </schema>field
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />name:属性的名称。 type:字段的数据结构类型,所用到的类型需要在fieldType中设置。 default:默认值。 indexed:是否创建索引只有index=true 的字段才能做facet.field的字段,同时只有index=true该 字段才能当做搜索的内容,当然store=true或者false没关系,将不需要被用于搜索的,而只是作为结果返 回的field的indexed设置为false stored:是否存储原始数据(如果不需要存储相应字段值,尽量设为false),表示是否需要把域值存储到 硬盘上,方便你后续查询时能再次提取出来原样显示给用户 docValues:表示此域是否需要添加一个 docValues 域,这对 facet 查询, group 分组,排序, function 查询有好处,尽管这个属性不是必须的,但他能加快索引数据加载,对 NRT 近实时搜索比较友 好,且更节省内存,但它也有一些限制,比如当前docValues 域只支持 strField,UUIDField,Trie*Field 等域,且要求域的域值是单值不能是多值域 multValued:是否有多个值,比如说一个用户的所有好友id。(对可能存在多值的字段尽量设置为 true,避免建索引时抛出错误) omitNorms:此属性若设置为 true ,即表示将忽略域值的长度标准化,忽略在索引过程中对当前域的权 重设置,且会节省内存。只有全文本域或者你需要在索引创建过程中设置域的权重时才需要把这个值设 false, 对于基本数据类型且不分词的域如intFeild,longField,Stre, 否则默认就是 false. required:添加文档时,该字段必须存在,类似MySQL的not null termVectors: 设置为 true 即表示需要为该 field 存储项向量信息,当你需要MoreLikeThis 功能 时,则需要将此属性值设为 true ,这样会带来一些性能提升。 termPositions: 是否存储 Term 的起始位置信息,这会增大索引的体积,但高亮功能需要依赖此项设 置,否则无法高亮 termOffsets:表示是否存储索引的位置偏移量,高亮功能需要此项配置,当你使用SpanQuery 时,此 项配置会影响匹配的结果集 field的定义相当重要,有几个技巧需注意一下,对可能存在多值得字段尽量设置 multiValued属性为 true,避免建索引是抛出错误;如果不需要存储相应字段值,尽量将stored属性设为false。dynamicField(动态域)
<dynamicField name="*_i" type="string" indexed="true" stored="true" />Name:动态域的名称,是一个表达式,*匹配任意字符,只要域的名称和表达式的规则能够匹配就可以使用。
例如:搜索时查询条件[product_i:钻石]就可以匹配这个动态域,可以直接使用,不用单独再定义一个product_i域。
uniqueKey
<uniqueKey>id</uniqueKey>相当于主键,每个文档中必须有一个id域。
copyField(复制域)
<copyField source="cat" dest="text"/>可以将多个Field复制到一个Field中,以便进行统一的检索。当创建索引时,solr服务器会自动的将源域的内容复制到目标域中
source:源域
dest:目标域,搜索时,指定目标域为默认搜索域,可以提高查询效率
定义目标域:
<field name="text" type="text_general" indexed="true" stored="false" multiValued="true"/>目标域必须要使用:multiValued=“true”
fieldType(域类型)
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" /> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" /> <filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType>name: 域类型名称,用于Field定义中的type属性引用 class: 存放该类型的值来进行索引的字段类名(同lucene中Field的子类)。注意,应以 solr.为前 缀,这样solr就可以很快定位到该到哪个包中去查找类,如 solr.TextField 。如果使用的是第三方包 的类,则需要用全限定名。 positionIncrementGap: 用于多值字段,定义多值间的间隔,来阻止假的短语匹配 autoGeneratePhraseQueries: 用于文本字段,如果设为true,solr会自动对该字段的查询生成短语 查询,即使搜索文本没带“” synonymQueryStyle: 同义词查询分值计算方式 enableGraphQueries: 是否支持图表查询 analyzer: 指定分词器。在FieldType定义的时候最重要的就是定义这个类型的数据在建立索引和进行查 询的时候要使用的分析器analyzer,包括分词和过滤。 type: index和query。Index 是创建索引,query是查询索引。 tokenizer: 指定分词器 filter: 指定过滤器分词器
solr7自带分词中文分词器
复制jar包
cp contrib/analysis-extras/lucene-libs/lucene-analyzers-smartcn-7.7.3.jar solr/WEB-INF/lib复制新项目的配置文件
创建solrcore mkdir solrhome/new_core cp -r server/solr/configsets/_default/conf solrhome/new_core/然后到solrhome/new_core/conf目录中打开managed-schema文件,增加如下代码
<fieldType name="text_hmm_chinese" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> <tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/> </analyzer> </fieldType>重启tomcat
访问项目,测试分词效果
IK中文分词器
下载分词器
一般解决分词问题会选择ikanalyzer,因为相对来说ikanalyzer更新的比较的好, solr7 本身提供中文的分词jar包,在此一并讲一下
下载solr7版本的ik分词器,下载地址:http://search.maven.org/#search%7Cga%7C1%7Ccom.github.magese
分词器GitHub源码地址:https://github.com/magese/ik-analyzer-solr7
将下载好的jar包放入 tomcat 对应的项目的 /WEB-INF/lib目录中
复制新项目配置文件
创建solrcore mkdir solrhome/ik cp -r server/solr/configsets/_default/conf solrhome/ik/然后到server/solr/ik/conf目录中打开managed-schema文件,增加如下代码
<!-- ik分词器 --> <fieldType name="text_ik" class="solr.TextField"> <analyzer type="index"> <tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType>重启tomcat
访问项目
停用词和同义词
停用词 <analyzer> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.StopFilterFactory" words="stopwords.txt"/> </analyzer> - words属性指定停用词文件的绝对路径或相对solr主目录下conf/目录的相对路径 - 停用词定义语法:一行一个 如: hello like同义词 <analyzer type="index"> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.SynonymGraphFilterFactory" synonyms="mysynonyms.txt"/> <filter class="solr.FlattenGraphFilterFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.SynonymGraphFilterFactory" synonyms="mysynonyms.txt"/> </analyzer>mysynonyms.txt: synonyms属性指定同义词文件的绝对路径或相对solr主目录下conf/目录的相对路径同义词定义语法:一类一行,如下表示,=>表示查询时标准化为后面的内容
couch,sofa,divan teh => the huge,ginormous,humungous => large small => tiny,teeny,weeny 瓷器 => 中国