Guava
示例代码见: https://gitee.com/ixinglan/others-cache-demo.git
1. 介绍
JVM缓存
堆缓存. 不能按照一定规则淘汰数据,并发处理能力差,针对并发可以使用CurrentHashMap,但缓存的其他功能要自行实现,缓存过期处理也要自己实现
Guava Cache
Guava是Google提供的一套Java工具包,而Guava Cache是一套非常完善的本地缓存机制(JVM缓存)。
Guava cache的设计来源于CurrentHashMap,可以按照多种策略来清理存储在其中的缓存值且保持很高的并发读写性能
2. 应用场景
对性能有非常高的要求
不经常变化
占用内存不大
有访问整个集合的需求
数据允许不时时一致
Guava Cache 的优势:
缓存过期和淘汰机制
在GuavaCache中可以设置Key的过期时间,包括访问过期和创建过期
GuavaCache在缓存容量达到指定大小时,采用LRU的方式,将不常使用的键值从Cache中删除
并发处理能力
GuavaCache类似CurrentHashMap,是线程安全的。
提供了设置并发级别的api,使得缓存支持并发的写入和读取
采用分离锁机制,分离锁能够减小锁力度,提升并发能力
分离锁是分拆锁定,把一个集合看分成若干partition,每个partiton一把锁。ConcurrentHashMap 就是分了16个区域,这16个区域之间是可以并发的。GuavaCache采用Segment做分区。
更新锁定
一般情况下,在缓存中查询某个key,如果不存在,则查源数据,并回填缓存。(CacheAside Pattern)
在高并发下会出现,多次查源并重复回填缓存,可能会造成源的宕机(DB),性能下降.
GuavaCache可以在CacheLoader的load方法中加以控制,对同一个key,只让一个请求去读源并回填缓存,其他请求阻塞等待。
集成数据源
一般我们在业务中操作缓存,都会操作缓存和数据源两部分
而GuavaCache的get可以集成数据源,在从缓存中读取不到时可以从数据源中读取数据并回填缓存
监控缓存加载/命中情况: 统计
3. 创建方式
CacheLoader
在创建cache对象时,采用CacheLoader来获取数据,当缓存不存在时能够自动加载数据到缓存中。
CallableCallback
4. 缓存数据删除
被动删除
基于数据大小删除
规则:LRU+FIFO , 访问次数一样少的情况下,FIFO
基于过期时间删除
隔多长时间后没有被访问过的key被删除
基于引用的删除
可以通过weakKeys和weakValues方法指定Cache只保存对缓存记录key和value的弱引用。这样当没有其他强引用指向key和value时,key和value对象就会被垃圾回收器回收。
主动删除
- 单独删除
- 批量删除
- 清空所有数据
5. Guava Cache原理
5.1 数据结构
GuavaCache的数据结构跟ConcurrentHashMap类似,但也不完全一样。最基本的区别是ConcurrentMap会一直保存所有添加的元素,直到显式地移除。
相对地,GuavaCache为了限制内存占用,通常都设定为自动回收元素。其数据结构图如下: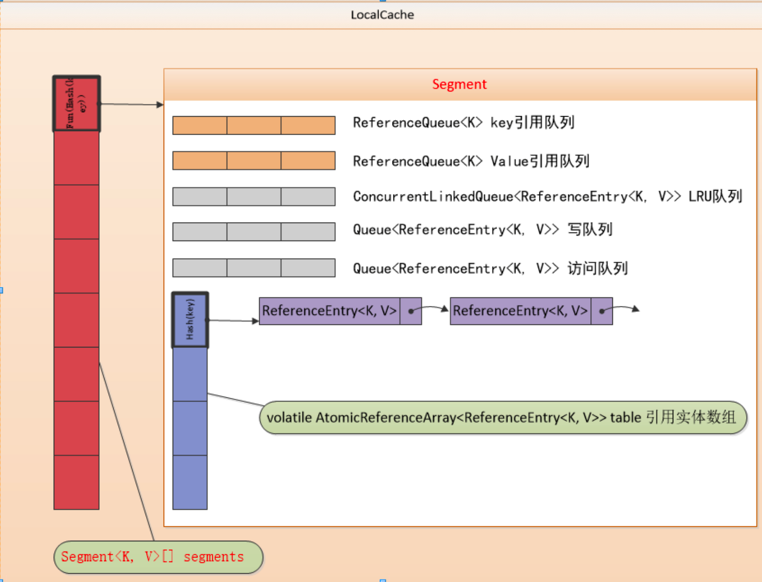
LocalCache为GuavaCache的核心类,包含一个Segment数组组成
Segement数组的长度决定了cache的并发数
每一个Segment使用了单独的锁,其实每个Segment继承了ReentrantLock,对Segment的写操作需要先拿到锁
每个Segment由一个table和5个队列组成
5个队列:
ReferenceQueue keyReferenceQueue:已经被GC,需要内部清理的键引用队列
ReferenceQueue valueReferenceQueue:已经被GC,需要内部清理的值引用队列
ConcurrentlinkedQueue<ReferenceEntry<k,v» recencyQueue:LRU队列,当segment上达到临界值发生写操作时该队列会移除数据 Queue<ReferenceEntry<K,V» writeQueue:写队列,按照写入时间进行排序的元素队列,写入一个元素时会把它加入到队列尾部 Queue<ReferenceEntry<K,V» accessQueue:访问队列,按照访问时间进行排序的元素队列,访问(包括写入)一个元素时会把它加入到队列尾部
1个table:
AtomicReferenceArray<ReferenceEntry<K,V» table:AtomicReferenceArray可以用原子方式更新其元素的对象引用数组
ReferenceEntry<k,v>
ReferenceEntry是GuavaCache中对一个键值对节点的抽象,每个ReferenceEntry数组项都是一条ReferenceEntry链。并且一个ReferenceEntry包含key、hash、valueReference、next字段(单链)
GuavaCache使用ReferenceEntry接口来封装一个键值对,而用ValueReference来封装Value值
5.2 回收机制
基于容量回收
在缓存项的数目达到限定值之前,采用LRU的回收方式
定时回收
expireAfterAccess:缓存项在给定时间内没有被读/写访问,则回收。回收顺序和基于大小回收一样(LRU)
expireAfterWrite:缓存项在给定时间内没有被写访问(创建或覆盖),则回收
基于引用回收
通过使用弱引用的键、或弱引用的值、或软引用的值,GuavaCache可以垃圾回收
GuavaCache构建的缓存不会"自动"执行清理和回收工作,也不会在某个缓存项过期后马上清理,也没有诸如此类的清理机制
GuavaCache是在每次进行缓存操作的时候,惰性删除如get()或者put()的时候,判断缓存是否过期
5.3 Segment定位
先通过key做hash定位到所在的Segment
通过位运算找首地址的偏移量SegmentCount>=并发数且为2的n次方
V get(K key, CacheLoader<? super K, V> loader) throws ExecutionException{
// 注意,key不可为空
int hash = hash(checkNotNull(key));
// 通过hash定位到segment数组的某个Segment元素,然后调用其get方法
return segmentFor(hash).get(key, hash, loader);
}
再找到segment中的Entry链数组,通过key的hash定位到某个Entry节点
6. 高级实战
6.1 并发操作
并发设置
GuavaCache通过设置 concurrencyLevel 使得缓存支持并发的写入和读取
LoadingCache<String,Object> cache = CacheBuilder.newBuilder() // 最大3个 同时支持CPU核数线程写缓存 .maximumSize(3) .concurrencyLevel(Runtime.getRuntime().availableProcessors()) .build();concurrencyLevel=Segment数组的长度
同ConcurrentHashMap类似Guava cache的并发也是通过分离锁实现
LoadingCache采用了类似ConcurrentHashMap的方式,将映射表分为多个segment。segment之间可以并发访问,这样可以大大提高并发的效率,使得并发冲突的可能性降低了
更新锁定
GuavaCache提供了一个refreshAfterWrite定时刷新数据的配置项
如果经过一定时间没有更新或覆盖,则会在下一次获取该值的时候,会在后台异步去刷新缓存, 刷新时只有一个请求回源取数据,其他请求会阻塞(block)在一个固定时间段,如果在该时间段内没有获得新值则返回旧值
LoadingCache<String,Object> cache = CacheBuilder.newBuilder() // 最大3个 同时支持CPU核数线程写缓存 .maximumSize(3) .concurrencyLevel(Runtime.getRuntime().availableProcessors()) //3秒内阻塞会返回旧数据,防止缓存击穿 .refreshAfterWrite(3,TimeUnit.SECONDS).build();
6.2 动态加载
动态加载行为发生在获取不到数据或者是数据已经过期的时间点,Guava动态加载使用回调模式
用户自定义加载方式,然后Guava cache在需要加载新数据时会回调用户的自定义加载方式
segmentFor(hash).get(key, hash, loader)
loader即为用户自定义的数据加载方式,当某一线程get不到数据会去回调该自定义加载方式去加载数据, 如callable
6.3 自定义LRU算法
见代码示例
6.4 常见问题
是否会oom
会,当我们设置缓存永不过期(或者很长),缓存的对象不限个数(或者很大)时
解决方案:缓存时间设置相对小些,使用弱引用方式存储对象
缓存到期会立即清除吗
不是的,GuavaCache是在每次进行缓存操作的时候,如get()或者put()的时候,判断缓存是否过期
个如果一个对象放入缓存以后,不在有任何缓存操作(包括对缓存其他key的操作),那么该缓存不会主动过期的
如何找出最久未使用的数据
用accessQueue,这个队列是按照LRU的顺序存放的缓存对象(ReferenceEntry)的。会把访问过的对象放到队列的最后
并且可以很方便的更新和删除链表中的节点,因为每次访问的时候都可能需要更新该链表,放入到链表的尾部
这样,每次从access中拿出的头节点就是最久未使用的
对应的writeQueue用来保存最久未更新的缓存队列,实现方式和accessQueue一样
7. 源码剖析
- 待续………….