Redis快速实战
1. 缓存原理与设计
1.1 缓存基本思想
使用场景
db缓存,减轻服务器压力;
提高系统响应;
做session分离;
做分布式锁 setNX;
做乐观锁 watch + incr;
缓存概念
缓存原指CPU上的一种高速存储器,它先于内存与CPU交换数据,速度很快
现在泛指存储在计算机上的原始数据的复制集,便于快速访问。
在互联网技术中,缓存是系统快速响应的关键技术之一
以空间换时间的一种技术(艺术)
大型网站缓存架构
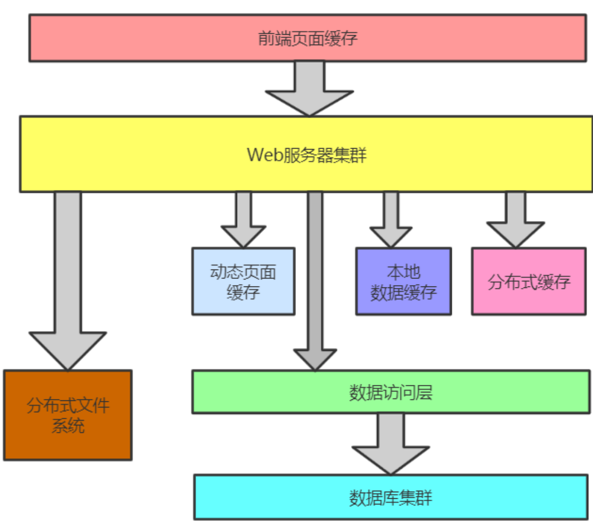
1.2 常见缓存分类
客户端缓存
页面缓存: Cookie、WebStorage(SessionStorage和LocalStorage)、WebSql、indexDB、Application Cache等
浏览器缓存: 强制缓存, 协商缓存
强制缓存:直接使用浏览器的缓存数据
<meta http-equiv="Cache-Control" content="max-age=7200" /> <meta http-equiv="Expires" content="Mon, 20 Aug 2010 23:00:00 GMT" />协商缓存:服务器资源未修改,使用浏览器的缓存(304);反之,使用服务器资源(200)。
<meta http-equiv="cache-control" content="no-cache">APP缓存: 如图片文件等
网络端缓存
web代理缓存: 可以缓存原生服务器的静态资源,如样式,图片等, ngix
边缘缓存: 如CDN
服务端缓存
数据库缓存: 如mysql InnoDB存储引擎中的buffffer-pool用于缓存InnoDB索引及数据块。
平台级缓存: 如guava cache, ehcache, oscache, 也称为服务器本地缓存
应用级缓存: redis, memcached, evcache(aws), tair(阿里) 集群支持,高性能,高并发,高扩展
1.3 缓存的优势及代价
优势:
- 提升用户体验
- 减轻服务器压力
- 提升系统性能
代价:
- 额外的硬件支出
- 高并发缓存失效
- 缓存与数据库同步
- 缓存并发竞争: 如多个redis客户端对同一个key进行set引发的并发问题
1.4 缓存的读写模式
Cache Aside Pattern(常用)
CacheAsidePattern(旁路缓存),是最经典的缓存+数据库读写模式。
读的时候,先读缓存,缓存没有的话,就读数据库,然后取出数据后放入缓存,同时返回响应。
缓存遍历需要时间, 因此写db的时候,删除缓存,等使用的时候再添加缓存,而不是更新缓存
并发脏读的三种情况 1.先更新数据库,再更新缓存 update与commit之间,更新缓存,commit失败 则DB与缓存数据不一致 2、先删除缓存,再更新数据库 update与commit之间,有新的读,缓存空,读DB数据到缓存数据是旧的数据 commit后DB为新数据则DB与缓存数据不一致 3、先更新数据库,再删除缓存(推荐) update与commit之间,有新的读,缓存空,读DB数据到缓存数据是旧的数据 commit后DB为新数据则DB与缓存数据不一致,采用延时双删策略Read/Write Through Pattern
应用程序只操作缓存,缓存操作数据库。
- Read-Through(穿透读模式/直读模式):应用程序读缓存,缓存没有,由缓存回源到数据库,并写入缓存。(guavacache)
- Write-Through(穿透写模式/直写模式):应用程序写缓存,缓存写数据库。该种模式需要提供数据库的handler,开发较为复杂。
Write Behind Caching Pattern
应用程序只更新缓存。
缓存通过异步的方式将数据批量或合并后更新到DB中,不能时时同步,甚至会丢数据
1.5 缓存架构设计思路
多层次
如本地缓存+分布式缓存结合
数据类型
采用简单数据类型: 用memcached
复杂数据类型: redis
要做集群
redis分布式缓存集群方案: codis, 哨兵+主从, redisCluster
缓存的数据结构设计
与数据库表一致
经常访问的,如用户表, 商品表
与数据库表不一致
需要存储关系,聚合,计算等,比如某个用户的帖子、用户的评论
2. Redis简介和安装
2.1 简介
Redis (Remote Dictionary Server)远程字典服务器,是用C语言开发的一个开源的高性能**键对( key-value )**内存数据库。
它提供了五种数据类型来存储值:字符串类型、散列类型、列表类型、集合类型、有序集合类型
它是一种 NoSQL 数据存储。
发展史
2008年,意大利的一家创业公司 Merzia 推出了一款基于 MySQL 的网站实时统计系统 LLOOGG ,然而没
过多久该公司的创始人 Salvatore Sanfilippo ( antirez)便 对MySQL的性能感到失望,于是他决
定亲自为 LLOOGG 量身定做一个数据库,并于2009年开发完成,这个数据库就是Redis。
Redis2.6
Redis2.6在2012年正式发布,主要特性如下:
服务端支持Lua脚本、去掉虚拟内存相关功能、键的过期时间支持毫秒、从节点提供只读功能、
两个新的位图命令:bitcount和bitop、重构了大量的核心代码、优化了大量的命令。
Redis2.8
Redis2.8在2013年11月22日正式发布,主要特性如下:
添加部分主从复制(增量复制)的功能、可以用bind命令绑定多个IP地址、Redis设置了明显的进程
名、发布订阅添加了pubsub命令、RedisSentinel生产可用
Redis3.0
Redis3.0在2015年4月1日正式发布,相比于Redis2.8主要特性如下:
RedisCluster:Redis的官方分布式实现(Ruby)、全新的对象编码结果、
lru算法大幅提升、部分命令的性能提升
Redis3.2
Redis3.2在2016年5月6日正式发布,相比于Redis3.0主要特征如下:
添加GEO相关功能、SDS在速度和节省空间上都做了优化、新的List编码类型
:quicklist、从节点读取过期数据保证一致性、Lua脚本功能增强等
Redis4.0
Redis4.0在2017年7月发布,主要特性如下:
提供了模块系统,方便第三方开发者拓展Redis的功能、PSYNC2.0:
优化了之前版本中,主从节点切换必然引起全量复制的问题、提供了新的缓存剔除算法:
LFU(LastFrequentlyUsed),并对已有算法进行了优化、提供了RDB-AOF混合持久化格式等
应用场景:
- 缓存使用,减轻DB压力
- DB使用,用于临时存储数据(字典表,购买记录)
- 解决分布式场景下Session分离问题(登录信息)
- 任务队列(秒杀、抢红包等等)
- 乐观锁
- 应用排行榜zset
- 签到bitmap
- 分布式锁
- 冷热数据交换
2.2 Redis单机版安装
mac下安装: 可通过brew或者直接下载客户端
brew cask install redis
linux安装:
官网地址:http://redis.io/ 中文官网地址:http://www.redis.cn/ 下载地址:http://download.redis.io/releases/
安装c语言gcc环境
yum install -y gcc-c++下载并解压缩包
wget http://download.redis.io/releases/redis-5.0.5.tar.gz tar -zxf redis-5.0.5.tar.gz进入目录, 编译
make安装redis,需要通过 PREFIX 指定安装路径
mkdir /usr/redis -p make install PREFIX=/usr/redis启动
# 前端启动: 启动命令: redis-server ,直接运行 bin/redis-server 将以前端模式启动 ./redis-server # 后端启动: # 1. 拷贝 redis-5.0.5/redis.conf 配置文件到 Redis 安装目录的 bin 目录 # 2. 修改 redis.conf # 将`daemonize`由`no`改为`yes` daemonize yes # 默认绑定的是回环地址,默认不能被其他机器访问 # bind 127.0.0.1 # 是否开启保护模式,由yes该为no protected-mode no # 3.启动 ./redis-server redis.conf关闭
./redis-cli shutdown命令说明
redis-server :启动 redis 服务 redis-cli :进入 redis 命令客户端 redis-benchmark : 性能测试的工具 redis-check-aof : aof 文件进行检查的工具 redis-check-dump : rdb 文件进行检查的工具 redis-sentinel : 启动哨兵监控服务redis命令行客户端
./redis-cli -h localhost -p 6379
3. redis客户端访问
3.1 java访问redis
采用jedis API进行访问即可
示例代码[jedis-demo]: https://gitee.com/ixinglan/redis-base-demo.git
3.2 spring 访问redis
见示例代码: spring-demo
3.3 spring boot 访问redis
见示例代码: spring-boot-demo
4.redis数据类型选择和应用场景
key的类型是字符串。
value的数据类型有:
常用的:string字符串类型、list列表类型、set集合类型、sortedset(zset)有序集合类型、hash类型。
不常见的:bitmap位图类型、geo地理位置类型。
Redis5.0新增一种:stream类型
注意:Redis中命令是忽略大小写,(set SET),key是不忽略大小写的 (NAME name)
4.1 key的设计
用:分割
把表名转换为key前缀, 比如: user:
第二段放置主键值
第三段放置列名
username 的 key: user:9:username
4.2 string字符串类型
Redis的String能表达3种值的类型:字符串、整数、浮点数 100.01 是个六位的串
| 命令名称 | 例 | 描述 |
|---|---|---|
| set | set key value | 赋值 |
| get | get key | 取值 |
| getset | getset key value | 取值并赋值 |
| setnx | setnx key value | 当key不存在时才用赋值 set key value NX PX 3000原子操作,px设置毫秒数 |
| append | append key value | 向尾部追加值 |
| strlen | strlen key | 获取字符串长度 |
| incr | incr key | 递增数字 |
| incrby | incrby key increment | 增加指定的整数 |
| decr | decr key | 递减数字 |
| decrby | decrby key decrement | 递减指定的整数 |
incr: 用于乐观锁
setnx: 用于分布式锁
4.3 list列表类型
list列表类型可以存储有序、可重复的元素
获取头部或尾部附近的记录是极快的
list的元素个数最多为2^32-1个(40亿)
| 名称 | 格式 | 描述 |
|---|---|---|
| lpush | lpush key v1,v2,v3… | 从左侧插入列表 |
| lpop | lpop key | 从左侧取出 |
| rpush | rpush key v1,v2,v3… | 从右侧插入 |
| rpop | rpop key | 从右侧取出 |
| lpushx | lpushx key value | 将值插入到头部 |
| rpushx | rpushx key value | 将值插入到尾部 |
| blpop | blpop key timeout | 从列表左侧取出,当列表为空时阻塞,可以设置最大阻塞时间 |
| brpop | brpop key timeout | 从列表右侧取出,当列表为空时阻塞,可以设置最大阻塞时间 |
| llen | llen key | 获取列表中个数 |
| lindex | lindex key index | 获取下标为Index的元素,从0开始 |
| lrange | lrange key start end | 返回指定区间的元素 |
| lrem | lrem key count value | 删除列表中的与value相待的元素 当count>0时,lrem会从列表的左边开始删除 当count<0时,lrem会从列表的后边开始删除 当count=0时,删除所有值为value的元素 |
| lset | lset key index value | 将列表index位置的元素设置成value的值 |
| ltrim | ltrim key start end | 对列表进行修剪,只保留start到end区间 |
| rpoplpush | rpoplpush key1,key2 | 将key1列表右侧弹出并插入到key2列表左侧 |
| brpoplpush | brpoplpush key1, key2 | 将key1列表右侧弹出并插入到key2列表左侧,会阻塞 |
| insert | insert key BEFORE/AFTER pivot value | 将value插入到列表,且位于值pivot之前或之后 |
应用场景:
1、作为栈或队列使用: 列表有序可以作为栈和队列使用
2、可用于各种列表,比如用户列表、商品列表、评论列表等。
4.4 set集合类型
无序、唯一元素
集合中最大的成员数为 2^32 - 1
| 命令 | 格式 | 描述 |
|---|---|---|
| sadd | sadd key m1 m2 m3… | 添加新成员 |
| srem | srem key m1 m2 m3… | 删除指定成员 |
| smembers | smembers key | 获得集合中所有元素 |
| spop | spop key | 返回一个随机元素,并将该元素删除 |
| srandmember | srandmember key | 返回一个随机元素,但不会删除 |
| scard | scard key | 获得集合中元素的数量 |
| sismember | sismember key member | 判断元素是否在集合内 |
| sinter | sinter key1 key2 key3 | 多集合的交集 |
| sdiff | sdiff key1 key2 key3 | 多集合的差集 |
| sunion | sunion key1 key2 key3 | 多集合的并集 |
适用于不能重复的且不需要顺序的数据结构
比如:关注的用户,还可以通过spop进行随机抽奖
4.5 sortedset有序集合类型
SortedSet(ZSet) 有序集合: 元素本身是无序不重复的
每个元素关联一个分数(score), 可按分数排序,分数可重复
| 命令 | 格式 | 描述 |
|---|---|---|
| zadd | zadd key score1 m1 sorce2 m2 | 为有序集合添加新成员 |
| zrem | zrem key m1 m2 | 删除指定成员 |
| zcard | zcard key | 获取元素数量 |
| zcount | zcount key min max | 返回score值在[min, max]区间的元素数量 |
| zincrby | zincrby key increment member | 在集合的member分值上加increment |
| zscore | zscore key member | 获取集合中member的分值 |
| zrank | zrank key member | 获取集合中member的排名(按分值从小到大) |
| zrevrank | zrevrank key member | 获取集合中member的排名(按分值从大到小) |
| zrange | zrange key start end | 获取集合中指定区间成员,按分数递增排序 |
| zrevrange | zrevrange key start end | 获取集合中指定区间成员,按分数递减排序 |
由于可以按照分值排序,所以适用于各种排行榜。比如:点击排行榜、销量排行榜、关注排行榜等
4.6 hash类型
Redis hash 是一个 string 类型的 fifield 和 value 的映射表,它提供了字段和字段值的映射。
每个 hash 可以存储 2^32 - 1 键值对(40多亿)。
| 命令 | 格式 | 描述 |
|---|---|---|
| hset | hset key field value | 赋值,不区别新增或修改 |
| hmset | hmset key field1 value1 field2 value2 | 批量赋值 |
| hsetnx | hsetnx key field value | 赋值,如果field存在则不操作 |
| hexists | hexists key field | 查看field是否存在 |
| hget | hget key field | 获取一个字段值 |
| hmget | hmget key field1 field2… | 获取多个字段值 |
| hgetall | hgetall key | |
| hdel | hdel key field1 field2… | 删除指定字段 |
| hincrby | hincrby key field increment | 指定字段自增increment |
| hlen | hlen key | 获取字段数量 |
应用场景:对象的存储 ,表数据的映射
4.7 bitmap位图类型
bitmap是进行位操作的, 通过一个bit位来表示某个元素对应的值或者状态,其中的key就是对应元素本身。
bitmap本身会极大的节省储存空间。
| 命令 | 格式 | 描述 |
|---|---|---|
| setbit | setbit key offset value | 设置key在offset处的bit值(只能是0 或1) |
| getbit | getbit key offset | 获取key在offset处的bit值 |
| bitcount | bitcount key | 获得key的bit位为1的个数 |
| bitpos | bitpos key value | 返回第一个被设置为bit值的索引值 |
| bitop | bitop and[or/xor/not] destkey key | 对多个key 进行逻辑运算后存入destkey 中 |
应用场景:
1、用户每月签到,用户id为key , 日期作为偏移量 1表示签到
2、统计活跃用户, 日期为key,用户id为偏移量 1表示活跃
3、查询用户在线状态, 日期为key,用户id为偏移量 1表示在线
4.8 geo地理位置类型
geo是Redis用来处理位置信息的。在Redis3.2中正式使用。主要是利用了Z阶曲线、Base32编码和geohash算法
z阶曲线
在x轴和y轴上将十进制数转化为二进制数,采用x轴和y轴对应的二进制数依次交叉后得到一个六位数编码。把数字从小到大依次连起来的曲线称为Z阶曲线,Z阶曲线是把多维转换成一维的一种方法。
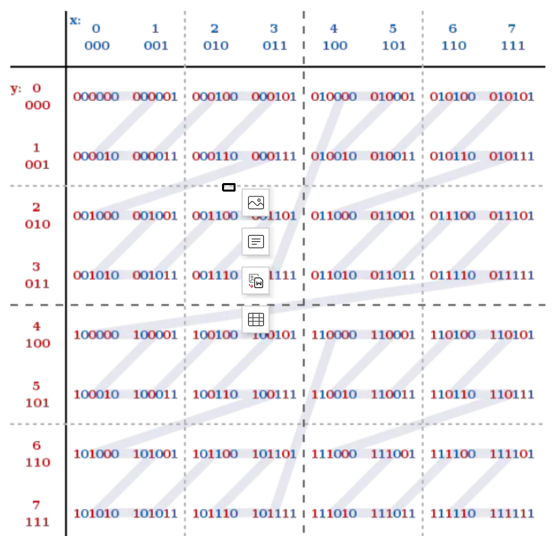
Base32编码
Base32这种数据编码机制,主要用来把二进制数据编码成可见的字符串,其编码规则是:任意给定一个二进制数据,以5个位(bit)为一组进行切分(base64以6个位(bit)为一组),对切分而成的每个组进行编码得到1个可见字符。Base32编码表字符集中的字符总数为32个(0-9、b-z去掉a、i、l、o),这也是Base32名字的由来。
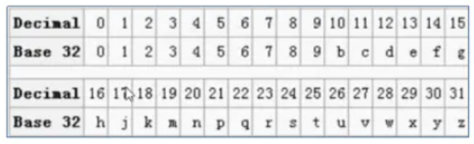
geohash算法
Gustavo在2008年2月上线了geohash.org网站。Geohash是一种地理位置信息编码方法。 经过geohash映射后,地球上任意位置的经纬度坐标可以表示成一个较短的字符串。可以方便的存储在数据库中,附在邮件上,以及方便的使用在其他服务中。以北京的坐标举例,[39.928167,116.389550]可以转换成 wx4g0s8q3jf9 。
Redis中经纬度使用52位的整数进行编码,放进zset中,zset的value元素是key,score是GeoHash的52位整数值。在使用Redis进行Geo查询时,其内部对应的操作其实只是zset(skiplist)的操作。通过zset的score进行排序就可以得到坐标附近的其它元素,通过将score还原成坐标值就可以得到元素的原始坐标。
| 命令 | 格式 | 描述 |
|---|---|---|
| geoadd | geoadd key 经度 纬度 m1 经度 纬度 m2.. | 添加地平坐标 |
| geohash | geohash key m1 m2 … | 返回标准的geohash 串 |
| geopos | geopos m1 m2… | 返回成员经纬度 |
| geodist | geodist key m1 m2 单位 | 计算成员间距离 |
| georadiusbymember | georadiusbymember key member 值单位 count 数 asc[desc] | 根据成员查找附近的成员 |
应用场景:
1、记录地理位置
2、计算距离
3、查找"附近的人"
georadiusbymember user:addr zhangf 20 km withcoord withdist count 3 asc
# 获得距离zhangf 20km 以内的按由近到远的顺序排出前三名的成员名称、距离及经纬度
withcoord : 获得经纬度
withdist:获得距离
withhash:获得geohash码
4.9 stream数据流类型
stream是Redis5.0后新增的数据结构,用于可持久化的消息队列。
几乎满足了消息队列具备的全部内容,包括:
消息ID的序列化生成
消息遍历
消息的阻塞和非阻塞读取
消息的分组消费
未完成消息的处理
消息队列监控
每个Stream都有唯一的名称,它就是Redis的key,首次使用 xadd 指令追加消息时自动创建。
| 命令 | 格式 | 描述 |
|---|---|---|
| xadd | xadd key id <*> field1 value1… | 将指定消息数据追加到指定队列(key)中, * 表示最新生成的id(当前时间+序列号) |
| xread | xread [COUNT count] [BLOCK milliseconds] STREAMS key [key …] ID [ID …] | 从消息队列中读取,count:读取条数, block:阻塞读(默认不阻塞), key:队列名称, id:消息id |
| xrange | xrange key start end [count] | 读取队列中给定ID范围的消息 COUNT:返回消息条数(消息id从小到大) |
| xrevrange | xrevrange key start end [count] | 读取队列中给定ID范围的消息 COUNT:返回消息条数(消息id从大到小) |
| xdel | xdel key id | 删除队列消息 |
| xgroup | xgroup create key groupname id xgroup destroy key groupname xgroup delconsumer key groupname cname xgroup setid key id | 创建一个新的消费组 删除指定消费组 删除指定消费组中的某个消费者 修改指定消息的最大id |
| xreadgroup | xreadgroup group groupname consumer COUNT streams key | 从队列中的消费组中创建消费者并消费数据(consumer不存在则创建) |
应用场景:消息队列的使用
127.0.0.1:6379> xadd topic:001 * name zhangfei age 23
"1591151905088-0"
127.0.0.1:6379> xadd topic:001 * name zhaoyun age 24 name diaochan age 16
"1591151912113-0"
127.0.0.1:6379> xrange topic:001 - +
1) 1) "1591151905088-0"
2) 1) "name"
2) "zhangfei"
3) "age"
4) "23"
2) 1) "1591151912113-0"
2) 1) "name"
2) "zhaoyun"
3) "age"
4) "24"
5) "name"
6) "diaochan"
7) "age"
8) "16"
127.0.0.1:6379> xread COUNT 1 streams topic:001 0
1) 1) "topic:001"
2) 1) 1) "1591151905088-0"
2) 1) "name"
2) "zhangfei"
3) "age"
4) "23"
#创建的group1
127.0.0.1:6379> xgroup create topic:001 group1 0
OK
# 创建cus1加入到group1 消费 没有被消费过的消息 消费第一条
127.0.0.1:6379> xreadgroup group group1 cus1 count 1 streams topic:001
1) 1) "topic:001"
2) 1) 1) "1591151905088-0"
2) 1) "name"
2) "zhangfei"
3) "age"
4) "23"
#继续消费 第二条
127.0.0.1:6379> xreadgroup group group1 cus1 count 1 streams topic:001
1) 1) "topic:001"
2) 1) 1) "1591151912113-0"
2) 1) "name"
2) "zhaoyun"
3) "age"
4) "24"
5) "name"
6) "diaochan"
7) "age"