Mycat实战
1. mycat安装
需先安装jdk
下载mycat-server工具包
解压
tar -zxvf Mycat-server-1.6.7.5-release-20200410174409-linux.tar.gz进入mycat/bin,启动Mycat
启动命令:./mycat start 停止命令:./mycat stop 重启命令:./mycat restart 查看状态:./mycat status访问mycat, 类似sharding-proxy
mysql -uroot -proot -h127.0.0.1 -P8066
2. 分片规则
常用分片规则
- 时间类:按天分片、自然月分片、单月小时分片
- 哈希类:Hash固定分片、日期范围Hash分片、截取数字Hash求模范围分片、截取数字Hash分片、一致性Hash分片
- 取模类:取模分片、取模范围分片、范围求模分片
- 其他类:枚举分片、范围约定分片、应用指定分片、冷热数据分片
常用配置示例
自动分片
<tableRule name="auto-sharding-long"> <rule> <columns>id</columns> <algorithm>rang-long</algorithm> </rule> </tableRule> <function name="rang-long" class="io.mycat.route.function.AutoPartitionByLong"> <property name="mapFile">autopartition-long.txt</property> </function>autopartition-long.txt文件内容如下:
# range start-end ,data node index # K=1000,M=10000. 0-500M=0 500M-1000M=1 1000M-1500M=2枚举分片
把数据分类存储
<tableRule name="sharding-by-intfile"> <rule> <columns>sharding_id</columns> <algorithm>hash-int</algorithm> </rule> </tableRule> <function name="hash-int" class="io.mycat.route.function.PartitionByFileMap"> <!-- 找不到分片时设置容错规则,把数据插入到默认分片0里面 --> <property name="mapFile">partition-hash-int.txt</property> <property name="defaultNode">0</property> </function>partition-hash-int.txt文件内容如下:
10000=0 10010=1取模分片
根据分片字段值 % 分片数 。
<tableRule name="mod-long"> <rule> <columns>id</columns> <algorithm>mod-long</algorithm> </rule> </tableRule> <function name="mod-long" class="io.mycat.route.function.PartitionByMod"> <!--分片数 --> <property name="count">3</property> </function>冷热数据分片
根据日期查询日志数据冷热数据分布 ,最近 n 个月的到实时交易库查询,超过 n 个月的按照 m 天分片。
<tableRule name="sharding-by-date"> <rule> <columns>create_time</columns> <algorithm>sharding-by-hotdate</algorithm> </rule> </tableRule> <function name="sharding-by-hotdate" class="org.opencloudb.route.function.PartitionByHotDate"> <!-- 定义日期格式 --> <property name="dateFormat">yyyy-MM-dd</property> <!-- 热库存储多少天数据 --> <property name="sLastDay">30</property> <!-- 超过热库期限的数据按照多少天来分片 --> <property name="sPartionDay">30</property> </function>一致性hash分片
<tableRule name="sharding-by-murmur"> <rule> <columns>id</columns> <algorithm>murmur</algorithm> </rule> </tableRule> <function name="murmur" class="io.mycat.route.function.PartitionByMurmurHash"> <!-- 默认是0 --> <property name="seed">0</property> <!-- 要分片的数据库节点数量,必须指定,否 则没法分片 --> <property name="count">2</property> <!-- 一个实际的数据库节点 被映射为这么多虚拟节点,默认是160倍,也就是虚拟节点数是物理节点数的160倍 --> <property name="virtualBucketTimes">160</property> <!-- <property name="weightMapFile">weightMapFile</property> 节点的权重, 没有指定权重的节点默认是1。以properties文件的格式填写, 以从0开始到count-1的整数值也就 是节点索引为key,以节点权重值为值。所有权重值必须是正整数,否则以1代替 --> <!-- <property name="bucketMapPath">/etc/mycat/bucketMapPath</property> 用于测试时观察各物理节点与虚拟节点的分布情况,如果指定了这个属性, 会把虚拟节点的 murmur hash值与物理节点的映射按行输出到这个文件,没有默认值,如果不指定,就不会输出任何 东西 --> </function>
3. 分库分表
server.xml: 数据库参数和用户及逻辑库等的配置
主键生成,为了方便,我们指定以文件的方式
<property name="sequenceHandlerType">0</property>user改成我们自定义的
<user name="root" defaultAccount="true"> <property name="password">123456</property> <property name="schemas">mycatdemo</property> <property name="defaultSchema">mycatdemo</property> </user>其他保持默认即可
schema.xml: 逻辑库,逻辑表,数据节点,数据节点主机等的定义
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
//1.逻辑库对应的数据节点
<schema name="mycatdemo" checkSQLschema="true" sqlMaxLimit="100" randomDataNode="dn1">
<table name="position" primaryKey="id" dataNode="dn1,dn2" rule="sharding-by-intfile" autoIncrement="true" fetchStoreNodeByJdbc="true">
</table>
</schema>
//2.数据节点配置,用之前测试的两个库
<dataNode name="dn1" dataHost="localhost1" database="sharding-demo1" />
<dataNode name="dn2" dataHost="localhost1" database="sharding-demo2" />
//3.数据节点对应的真实数据库连接
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="jdbc:mysql://localhost:3306" user="root"
password="123456">
</writeHost>
</dataHost>
</mycat:schema>
rule.xml: 分片规则配置
我们以mod_long示例
<tableRule name="mod-long"> <rule> <columns>id</columns> <algorithm>mod-long</algorithm> </rule> </tableRule> <function name="mod-long" class="io.mycat.route.function.PartitionByMod"> <!-- how many data nodes --> <property name="count">2</property> </function>将schema.xml里的分片规则改为mod-long
<table name="position" primaryKey="id" dataNode="dn1,dn2" rule="mod-long" autoIncrement="true" fetchStoreNodeByJdbc="true"> </table>
启动测试:
- bin目录下, 先执行
mycat install - 启动
./mycat start - 如果mac下无法启动,检查是否下载了对应版本, 或者是否系统隐私设置允许运行
- 注意连接时默认端口为8066
- 可以测试不同分片策略效果
4. 全局id
<property name="sequenceHandlerType">0</property>
前面已经讲过:
0表示使用本地文件方式;
1表示使用数据库方式生成;
2表示使用本地时间戳方式;
3表示基于ZK与本地配置的分布式ID生成器;
4表示使用zookeeper递增方式生成
zk暂时不考虑, 有些复杂, 其中其他分别对应以下properties配置文件 
Tips: 采取不同的序列id,有时要修改对应的分片策略,比如取时间戳为id, 则有的分片策略长度不够,导致写入不进去
如果采用数据库形式, 也提供了初始化序列表 dbseq.sql
5. 全局表
例如我们之前用过的city表
<table name="city" primaryKey="id" type="global" dataNode="dn1,dn2" />
6. 读写分离
在schema.xml文件中配置Mycat读写分离。使用前需要搭建MySQL主从架构,并实现主从复制,Mycat不负数据同步问题。
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="M1" url="localhost:3306" user="root" password="123456">
<readHost host="S1" url="localhost:3307" user="root" password="123456" weight="1" />
</writeHost>
</dataHost>
7. 读写分离高可用
balance参数:
0 : 所有读操作都发送到当前可用的writeHost
1 :所有读操作都随机发送到readHost和stand by writeHost
2 :所有读操作都随机发送到writeHost和readHost
3 :所有读操作都随机发送到writeHost对应的readHost上,但是writeHost不负担读压力
writeType参数:
0 : 所有写操作都发送到可用的writeHost
1 :所有写操作都随机发送到readHost
2 :所有写操作都随机发送到writeHost,readHost
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="M1" url="localhost:3306" user="root" password="123456"> </writeHost>
<writeHost host="S1" url="localhost:3307" user="root" password="123456"> </writeHost>
</dataHost>
6中的写法: 当写挂了读不可用,这种写法可以继续使用,事务内部的一切操作都会走写节点,所以读操作不要加事务,如果读延时较大,使用根据主从延时切换的读写分离,或者强制走写节点
8. 强制路由
一个查询 SQL 语句以/* !mycat * /注解来确定其是走读节点还是写节点。
/*! */
/*# */
/** */
强制走从:
/*!mycat:db_type=slave*/ select * from travelrecord //有效
/*#mycat:db_type=slave*/ select * from travelrecord
强制走写:
/*!mycat:db_type=master*/ select * from travelrecord //有效
/*#mycat:db_type=slave*/ select * from travelrecord
1.6 以后Mycat除了支持db_type注解以外,还有其他注解,如下:
/*!mycat:sql=sql */ 指定真正执行的SQL
/*!mycat:schema=schema1 */ 指定走那个schema
/*!mycat:datanode=dn1 */ 指定sql要运行的节点
/*!mycat:catlet=io.mycat.catlets.ShareJoin */ 通过catlet支持跨分片复杂SQL实现以及存 储过程支持等
9. 主从延时切换
switchType参数:
-1: 表示不自动切换
1 :表示自动切换
2 :基于MySQL主从同步状态决定是否切换
3 :基于MySQL cluster集群切换机制
1.4开始支持MySQL主从复制状态绑定的读写分离机制,让读更加安全可靠,配置如下:
MyCAT心跳检查语句配置为show slave status,dataHost上定义两个新属性:switchType="2"与slaveThreshold="100",此时意味着开启MySQL主从复制状态绑定的读写分离与切换机制,Mycat心跳机制通过检测show slave status中的"Seconds_Behind_Master",“Slave_IO_Running”,“Slave_SQL_Running"三个字段来确定当前主从同步的状态以及Seconds_Behind_Master主从复制时延,当Seconds_Behind_Master>slaveThreshold时,读写分离筛选器会过滤掉此Slave机器,防止读到很久之前的旧数据,而当主节点宕机后,切换逻辑会检查Slave上的Seconds_Behind_Master是否为0,为0时则表示主从同步,可以安全切换,否则不会切换。
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="2" slaveThreshold="100">
<heartbeat>show slave status </heartbeat>
<!-- can have multi write hosts -->
<writeHost host="M1" url="localhost:3306" user="root" password="123456"> </writeHost>
<writeHost host="S1" url="localhost:3316" user="root" password="123456"> </writeHost>
</dataHost>
1.4.1开始支持MySQL集群模式,让读更加安全可靠,配置如下:MyCAT心跳检查语句配置为show status like ‘wsrep%’,dataHost上定义两个新属性:switchType="3",此时意味着开启MySQL集群复制状态状态绑定的读写分离与切换机制,Mycat心跳机制通过检测集群复制时延时,如果延时过大或者集群出现节点问题不会负载改节点。
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="3" >
<heartbeat> show status like ‘wsrep%’</heartbeat>
<writeHost host="M1" url="localhost:3306" user="root"password="123456"> </writeHost>
<writeHost host="S1"url="localhost:3316"user="root"password="123456" > </writeHost>
</dataHost>
10. mycat事务
Mycat数据库事务
Mycat目前没有出来跨分片的事务强一致性支持,单库内部可以保证事务的完整性,如果跨库事务,在执行的时候任何分片出错,可以保证所有分片回滚,但是一旦应用发起commit指令,无法保证所有分片都成功,考虑到某个分片挂的可能性不大所以称为弱XA。
XA事务使用
Mycat从1.6.5版本开始支持标准XA分布式事务,考虑到MySQL5.7之前版本XA有bug,所以推荐最佳搭配XA功能使用MySQL5.7版本。
Mycat实现XA标准分布式事务,Mycat作为XA事务协调者角色,即使事务过程中Mycat宕机挂掉,由于Mycat会记录事务日志,所以Mycat恢复后会进行事务的恢复善后处理工作。考虑到分布式事务的性能开销比较大,所以只推荐在全局表的事务以及其他一些对一致性要求比较高的场景。
使用示例:XA操作说明
XA事务需要设置手动提交
set autocommit=0;使用该命令开启XA事务
set xa=on;执行相应的SQL语句部分
insert into city(id,name,province) values(200,'chengdu','sichuan'); update position set salary='300000' where id<5;提交或回滚事务
commit; 或者 rollback;
保证Repeatable Read
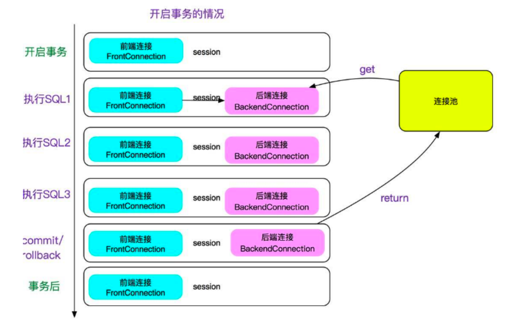
mycat有一个特性,就是开事务之后,如果不运行update/delete/select for update等更新类语句SQL的话,不会将当前连接与当前session绑定。如下图所示:
这样做的好处是可以保证连接可以最大限度的复用,提升性能。
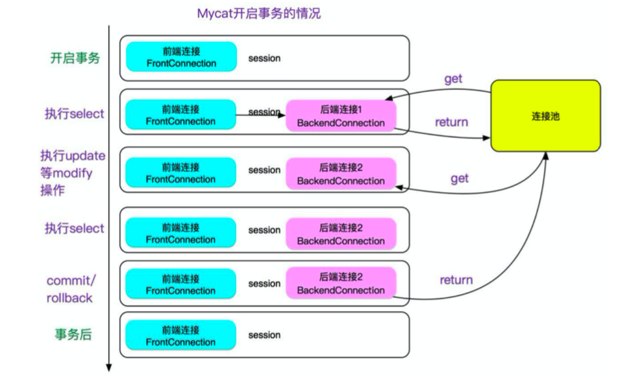
但是,这就会导致两次select中如果有其它的在提交的话,会出现两次同样的select不一致的现象,即不能Repeatable Read,这会让人直连MySQL的人很困惑,可能会在依赖Repeatable Read的场景出现问题。所以做了一个开关,当server.xml的system配置了
strictTxIsolation=true的时候,会关掉这个特性,以保证repeatable read,加了开关后如下图所示: