Lucene应用实战
1. 索引创建和搜索流程
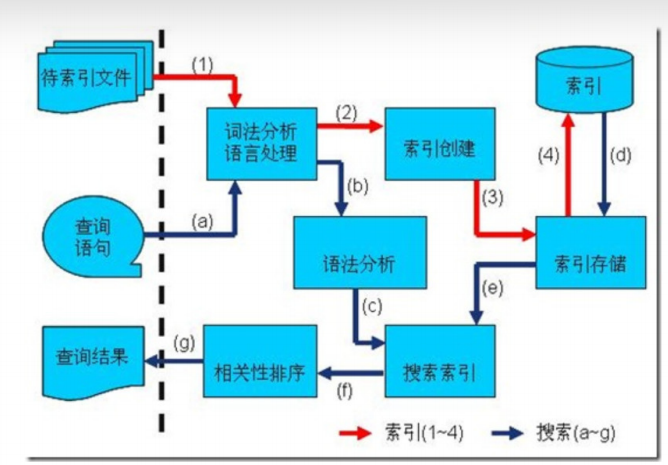
1.1 索引创建流程
一些要索引的原文档(Document)数据
采集数据分类: 1、对于互联网上网页,可以使用工具将网页抓取到本地生成html文件。 2、数据库中的数据,可以直接连接数据库读取表中的数据。 3、文件系统中的某个文件,可以通过I/O操作读取文件的内容。如我们要分析的数据内容是
Lucene Core is a Java library providing powerful indexing and search features, as well as spellchecking, hit highlighting and advanced analysis/tokenization capabilities. The PyLucene sub project provides Python bindings for Lucene Core.Solr is highly scalable, providing fully fault tolerant distributed indexing, search and analytics. It exposes Lucene's features through easy to use JSON/HTTP interfaces or native clients for Java and other languages.The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models.创建文档对象, 进行词法分析,语言处理, 将原文档传给分词器(Tokenizer)形成一系列词(Term)
索引创建 将得到的词(Term)传给索引组件(Indexer)形成倒排索引结构
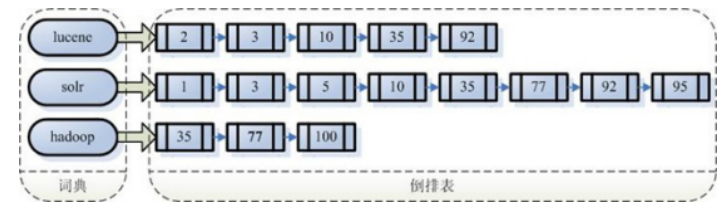
通过索引存储器, 将索引写入到磁盘
1.2 搜索过程
a) 用户输入查询语句
b) 对查询语句经过词法分析和语言分析得到一系列词(Term)
c) 通过语法分析得到一个查询树
d) 通过索引存储将索引读到内存
e) 利用查询树搜索索引,从而得到每个词(Term)的文档列表,对文档列表进行交、差、并得到结果文
档
f) 将搜索到的结果文档按照对查询语句的相关性进行排序
g) 返回查询结果给用户
2. Lucene索引创建和搜索实现
示例代码:lucene-index LuceneIndexTest#testCreateIndex/testSearchIndex
Luke作为Lucene工具包中的一个工具(https://github.com/DmitryKey/luke/releases),可以通过界面来进行索引文件的查询、修改
Lucene可以通过query对象输入查询语句。同数据库的sql一样,lucene也有固定的查询语法:最基本的有比如:AND, OR, NOT 等(必须大写)
如:
用户想找一个desc中包括java关键字和lucene关键字的文档。
它对应的查询语句:desc:java AND desc:lucene
3. Field域的使用
3.1 Field属性
Lucene存储对象是以Document为存储单元,对象中相关的属性值则存放到Field中
Field是文档中的域,包括Field名和Field值两部分,一个文档可以包括多个Field,Document只是Field的一个承载体,Field值即为要索引的内容,也是要搜索的内容
Field三大属性:
是否分词(tokenized)
是: 作分词处理,即将Field值进行分词,分词的目的是为了索引
比如:商品名称、商品简介等,这些内容用户要输入关键字搜索,由于搜索的内容格式不固定、内容多需要 分词后将语汇单元索引。
否: 不作分词处理
如: 订单号,身份证等
是否索引
是: 进行索引.将Field分词后的词或整个Field值进行索引,索引的目的是为了搜索
如: 商品名称,商品简介分词后进行索引,订单号,身份证号不用分词但要索引,这些将来都要作为查询条件
否:不索引.该域的内容无法搜索到
如:文件路径,图片路径等,不用作为查询条件的不用索引
是否存储
是: 将field值存储在文档中,存储在文档中的field才可以从document中获取
如: 商品名称,订单号,凡是将来要从document中获取的都要存储
否: 不存储field值,不存储的field无法通过document获取
如: 商品简介,内容较大不用存储.
3.2 Field常用类型
Field对应的类是 org.apache.lucene.document.Field ,该类实现了org.apache.lucene.document.IndexableField 接口, 代表用于indexing的一个字段。Field类比较底层一些,所以Lucene实现了许多Field子类,用于不同的场景
| Field类型 | 数据类型 | 是否分词 | 是否索引 | 是否存储 | 说明 |
|---|---|---|---|---|---|
| StringField( FieldName, FieldValue, Store.YES) | 字符串 | N | Y | Y/N | 字符串类型Field,不分词, 作为一个整体进行索引(如:身份证号,订单号) |
| TextField( FieldName, FieldValue, Store.NO) | 文本类型 | Y | Y | Y/N | 文本类型Field,分词并且索引 |
| LongField( FieldName, FieldValue, Store.YES) 或 LongPoint( String name , int… point )等 | 数值类型 | Y | Y | Y/N | 在Lucene6.0中, LongField替换为LongPoint, IntField替换为IntPoint,FloatField替换为 FloatPoint,DoubleField替换 为DoublePoint。 对数值型字段索引,索引不存储。要存储结 合StoredField即可 |
| StoredField( FieldName, FieldValue) | 支持多种类型 | N | N | Y | 构建不同类型的Field,不分词,不索引, 要存储(如:商品图片路径) |
3.3 Field示例代码
示例代码:lucene-index LuceneIndexTest#createIndexForField
4. 索引的维护
添加索引
indexWriter.addDocument(doc);索引删除
根据Term项删除索引,满足条件的将全部删除。
indexWriter.deleteDocuments(new Term("name", "game"));全部删除
indexWriter.deleteAll();更新索引
更新索引是先删除再添加,建议对更新需求采用此方法并且要保证对已存在的索引执行更新,可以先查询出来,确定更新记录存在执行更新操作
如果更新索引的目标文档对象不存在,则执行添加。
示例代码: lucene-index LuceneIndexTest
5. 分词器
5.1 分词器概念
采集到的数据会存储到Document对象的Field域中,分词器就是将Document中Field的value值切分成一个一个的词。
停用词: 停用词是为节省存储空间和提高搜索效率,搜索程序在索引页面或处理搜索请求时会自动忽略某些字或词,这些字或词即被称为Stop Words(停用词)。比如语气助词、副词、介词、连接词等,通常自身并无明确的意义,只有将其放入一个完整的句子中才有一定作用,如常见的“的”、“在”、“是”、“啊” 、 a、an、the 等
扩展词: 扩展词 就是分词器默认不会切出的词 但我们希望分词器切出这样的词 。
过滤:包括去除标点符号过滤、去除停用词过滤(的、是、a、an、the等)、大写转小写、词的形还原(复数形式转成单数形参、过去式转成现在式。。。)等。
5.2 分词器案例
对于分词来说,不同的语言,分词规则不同。Lucene作为一个工具包提供不同国家的分词器,本例子使用StandardAnalyzer,它可以对用英文进行分词。
示例代码: lucene-index AnalyzerTest
如下是org.apache.lucene.analysis.standard.StandardAnalyzer的部分源码:
protected TokenStreamComponents createComponents(String fieldName) {
final StandardTokenizer src = new StandardTokenizer();
src.setMaxTokenLength(this.maxTokenLength);
TokenStream tok = new LowerCaseFilter(src);
TokenStream tok = new StopFilter(tok, this.stopwords);
return new TokenStreamComponents(src, tok) {
protected void setReader(Reader reader) {
src.setMaxTokenLength(StandardAnalyzer.this.maxTokenLength);
super.setReader(reader);
}
};
}
Tokenizer就是分词器,负责将reader转换为语汇单元即进行分词处理,Lucene提供了很多的分词器,也可以使用第三方的分词,比如IKAnalyzer一个中文分词器
TokenFilter是分词过滤器,负责对语汇单元进行过滤,TokenFilter可以是一个过滤器链儿,Lucene提供了很多的分词器过滤器,比如大小写转换、去除停用词等。
如下是语汇单元的生成过程:创建一个Tokenizer分词器,经过三个TokenFilter生成语汇单元Token
Tokenizer —>TokenFilter(标准过滤)—>TokenFilter(大小写过滤)—>TokenFilter(停用词过滤)—->Tokens
5.3 中文分词器
英文是以单词为单位的,单词与单词之间以空格或者逗号句号隔开。所以对于英文,我们可以简单以空格判断某个字符串是否为一个单词,比如I love China,love 和 China很容易被程序区分开来
而中文则以字为单位,字又组成词,字和词再组成句子。中文“我是中国人”就不一样了,电脑不知道“中 国”是一个词语还是“是 中”是一个词语
把中文的句子切分成有意义的词,就是中文分词,也称切词.
如: 我是中国人: 我, 是, 我是, 中国, 人
Lucene自带中文分词器
StandardAnalyzer: 单字分词, 就是按照中文一个字一个字地进行分词
CJKAnalyzer: 按两个字进行切分, 如"我是中国人": 我是,是中,中国, 国人
两个都无法满足需求
中文分词器IKAnalyzer
IKAnalyzer继承Lucene的Analyzer抽象类,使用IKAnalyzer和Lucene自带的分析器方法一样,将Analyzer测试代码改为IKAnalyzer测试中文分词效果。
如果使用中文分词器ik-analyzer,就需要在索引和搜索程序中使用一致的分词器:IK-analyzer。
示例代码同上: lucene-index AnalyzerTest
5.4 扩展中文词库
如果想配置扩展词和停用词,就创建扩展词的文件和停用词的文件。
注意:不要用window自带的记事本保存扩展词文件和停用词文件,那样的话,格式中是含有bom的。
从ikanalyzer包中拷贝配置文件 拷贝到资源文件夹中
IKAnalyzer.cfg.xml配置文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic;</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic;</entry>
</properties>
中文词库,添加新词的地方 ext.dic
stopword.dic是存放停用词的地方
最终分词效果 和之前的分词器对比
6. 搜索实战
创建查询的两种方式:
使用lucene提供Query子类
Query是一个抽象类,lucene提供了很多查询对象,比如TermQuery项精确查询,WildcardQuery统配查询 各种Point的数字范围查询等
1.TermQuery 词项查询 2.BooleanQuery 布尔查询 3.PhraseQuery 短语查询 4.MultiPhraseQuery多重短语查询 5.SpanNearQuery 临近查询(跨度查询) 6.TermRangeQuery 词项范围查询 7.PrefixQuery,WildcardQuery,RegexpQuery 8.FuzzyQuery 模糊查询 9.数值查询使用QueryParser解析查询表达式
- 传统的解析器:QueryParser和MultiFieldQueryParser
- 基于新的 flflexible 框架的解析器:StandardQueryParser
TopDocs:
Lucene搜索结果可通过TopDocs遍历, 其提供了少量的属性,如下:
- totalHits: 匹配搜索条件的总记录数
- scoreDocs: 顶部匹配记录
注:
Search方法需要指定匹配记录数量n:search(query, n)
TopDocs.totalHits:是匹配索引库中所有记录的数量
TopDocs.scoreDocs:匹配相关度高的前边记录数组,scoreDocs的长度小于等于search方法指定的参数n
以下搜索示例代码: lucene-index QueryTest
6.1 Query子类搜索
TermQuery
不使用分词器, 精确匹配查找
BooleanQuery
布尔查询,实现组合条件查询
组合关系代表的意思如下: 1、MUST和MUST表示“与”的关系,即“交集”。 2、MUST和MUST_NOT前者包含后者不包含。 3、MUST_NOT和MUST_NOT没意义 4、SHOULD与MUST表示MUST,SHOULD失去意义; 5、SHOULD与MUST_NOT相当于MUST与MUST_NOT。 6、SHOULD与SHOULD表示“或”的关系,即“并集”。短语查询 PhraseQuery
跨度查询 SpanTermQuery
模糊查询 WildcardQuery
:通配符查询, *表示0个或多个字符,
?表示1个字符,
\是转义符
通配符查询可能会比较慢,不可以通配符开头(那样就是所有词项了)
数值查询
6.2 QueryParser搜索
查询语法
基础查询,关键词查询
域名+":"+搜索的关键字
如:name:java
范围查询
域名+":"+[最小值 TO 最大值]
如:size:[1 TO 1000]
注意:QueryParser不支持对数字范围的搜索,它支持字符串范围。数字范围搜索建议使用对应Point。
组合条件查询
第一种写法: 1)+条件1 + 条件2:两个条件之间是并且的关系and 例如:+filename:lucene + content:lucene 2)+条件1 条件2:必须满足第一个条件,应该满足第二个条件 例如:+filename:lucene content:lucene 3)条件1 条件2:两个条件满足其一即可。 例如:filename:lucene content:lucene 4)-条件1条件2:必须不满足条件1,要满足条件2 例如:-filename:lucene content:lucene 第二种写法: 条件1 AND 条件2 条件1 OR 条件2 条件1 NOT 条件2