Lucene基础
1. 数据检索的问题
原始方式

改进后的方式
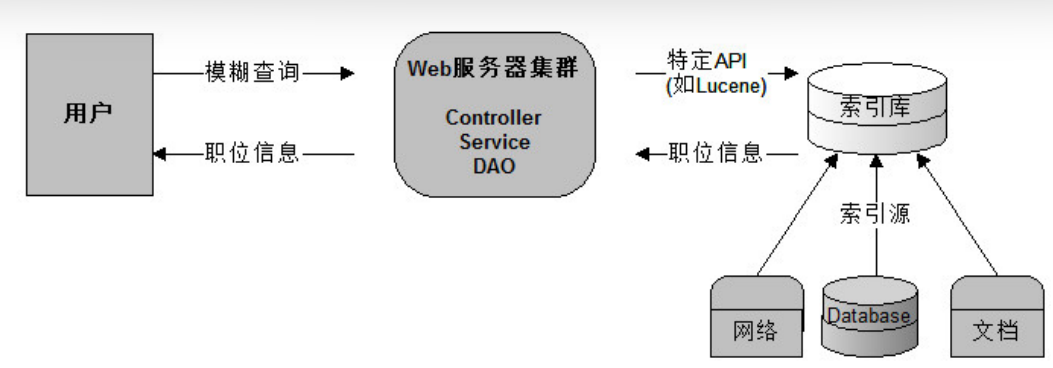
为了解决数据库压力和速度的问题,我们的数据库就变成了索引库,我们使用Lucene的API的来操作服务器上的索引库。这样完全和数据库进行了隔离
全文数据
我们生活中的数据总体分为两种:结构化数据 和非结构化数据 。
结构化数据: 指具有固定格式或有限长度的数据,如数据库中的数据,元数据等。 非结构化数据: 指不定长或无固定格式的数据,如邮件,word文档等。非结构化数据又一种叫法叫全文数据。
数据库适合结构化数据的精确查询,而不适合半结构化、非结构化数据的模糊查询及灵活搜索(特别是数据量大时),无法提供想要的实时性。
2. 全文数据查询方法
顺序扫描法
所谓顺序扫描,就是要找内容包含一个字符串的文件,就是一个文档一个文档的看
量大量效率低
全文检索
全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程
全文检索的基本思路,就是将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对这个有一定结构的数据进行搜索,从而达到搜索相对较快的目的
这部分从非结构化数据中提取出的然后重新组织的信息,我们称之索引 ,这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search) 。
全文检索与倒排索引
全文检索通常使用倒排索引(inverted index)来实现. 倒排索引同B树索引一样,也是一种索引结构。其中存储了单词与单词自身在一个或多个文档中所在位置之间的映射
正排索引
正排索引是指文档ID为key,表中记录每个关键词出现的次数 位置等,查找时扫描表中的每个文档中字的信息,直到找到所有包含查询关键字的文档
“文档1”的ID > 单词1:出现次数,出现位置列表;单词2:出现次数,出现位置列表;…………。 “文档2”的ID > 此文档出现的关键词列表。正常的索引一般是指关系型数据库里的索引。 把不同的数据存放到不同的字段中。如果要实现baidu或google那种搜索,就需要与一条记录的多个字段进行比对,需要 全表扫描,如果数据量比较大的话,性能就很低
当用户在主页上搜索关键词“华为手机”时,假设只存在正向索引(forward index),那么就需要扫描索引库中的所有文档,找出所有包含关键词“华为手机”的文档,再根据打分模型进行打分,排出名次后呈现给用户。因为互联网上收录在搜索引擎中的文档的数目是个天文数字,这样的索引结构根本无法满足实时返回排名结果的要求
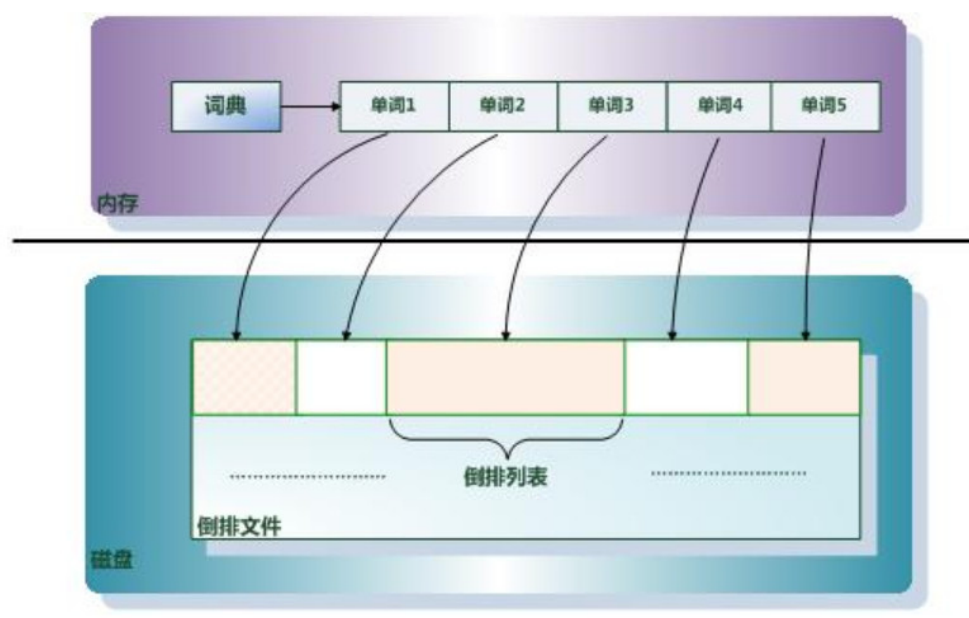
倒排索引
被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最常用的数据结构。通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。
“关键词1”:“文档1”的ID 出现次数 出现的位置,“文档2”的ID 出现次数 出现的位置,…………。 “关键词2”:带有此关键词的文档ID列表。倒排索引主要由两个部分组成:“单词词典”和“倒排文件”。
3. Lucene简介
Lucene的作者Doug Cutting是资深的全文索引/检索专家,最开始发布在他本人的主页上,2000年开 源,2001年10月贡献给APACHE,成为APACHE基金的一个子项目。官网 https://lucene.apache.org/core。现在是开源全文检索方案的重要选择。 Lucene是非常优秀的成熟的开源的免费的纯java语言的全文索引检索工具包。 Lucene是一个高性能、可伸缩的信息搜索(IR)库。 Information Retrieval (IR) library.它可以 为你的应用程序添加索引和搜索能力。 Lucene是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者 是以此为基础建立起完整的全文检索引擎。由Apache软件基金会支持和提供,Lucene提供了一个简单却强 大的应用程序接口,能够做全文索引和搜索。Lucene是当前以及最近几年非常受欢迎的免费Java信息检索 程序库。
Lucene的实现产品
Nutch: Apache顶级开源项目,包含网络爬虫和搜索引擎(基于lucene)的系统(同 百度、google)。Hadoop因它而生。
Solr : Lucene下的子项目,基于Lucene构建的独立的企业级开源搜索平台,一个服务。它提供了基于xml/JSON/http的api供外界访问,还有web管理界面
Elasticsearch:基于Lucene的企业级分布式搜索平台,它对外提供restful-web接口,让程序员可以轻松、方便使用搜索平台
还有大家所熟知的OSChina、Eclipse、MyEclipse、JForum等等都是使用了Lucene做搜索框架来实现自己的搜索部分内容,在我们自己的项目中很有必要加入他的搜索能力,可以大大提高我们开发系统的搜索体验度。
特性
稳定,索引性能高
每小时能够索引150GB以上的数据。
对内存的要求小 只需要1MB的堆内存
增量索引和批量索引一样快。
索引的大小约为索引文本大小的20%~30%。
高效,准确,高性能的搜索算法
范围搜索 - 优先返回最佳结果很多强大的良好的搜索排序
强大的查询方式支持:短语查询、通配符查询、临近查询、范围查询等
支持字段搜索(如标题、作者、内容)。
可根据任意字段排序
支持多个索引查询结果合并
支持更新操作和查询操作同时进行
支持高亮、join、分组结果功能
速度快
可扩展排序模块,内置包含向量空间模型、BM25模型可选
可配置存储引擎
跨平台
纯java编写。
模块构成
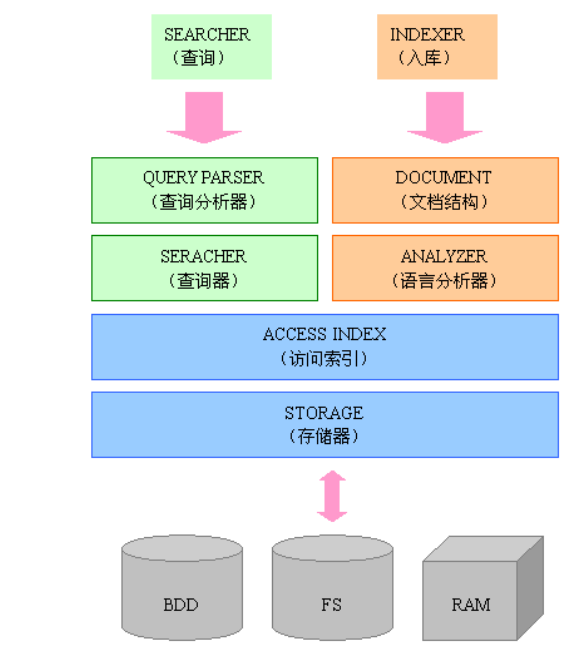
Lucene 的index模块主要负责索引的创建,里面有IndexWriter。 Lucene 的search模块主要负责对索引的搜索。 Lucene 的QueryParser主要负责语法分析。 Lucene 的Document相当于一个要进行索引的单元,任何可以想要被索引的文件都必须转化为Document 对象才能进行索引。代表一个虚拟文档与字段,其中字段是可包含在物理文档的内容,元数据等对象。 Lucene 的analysis 模块主要负责词法分析及语言处理而形成Term。 Lucene 的store模块主要负责索引的读写。