Kafka集群与运维
1. 集群应用场景
1.1 消息传递
Kafka可以很好地替代传统邮件代理。消息代理的使用有多种原因(将处理与数据生产者分离,缓冲未处理的消息等)。与大多数邮件系统相比,Kafka具有更好的吞吐量,内置的分区,复制和容错功能,这使其成为大规模邮件处理应用程序的理想解决方案。根据我们的经验,消息传递的使用通常吞吐量较低,但是可能需要较低的端到端延迟,并且通常取决于Kafka提供的强大的持久性保证。
在这个领域,Kafka与ActiveMQ或RabbitMQ等传统消息传递系统相当
1.2 网站活动的路由
Kafka最初的用例是能够将用户活动跟踪管道重建为一组实时的发布-订阅。这意味着将网站活动(页面浏览,搜索或用户可能采取的其他操作)发布到中心主题,每种活动类型只有一个主题。这些提要可用于一系列用例的订阅,包括实时处理,实时监控,以及加载到Hadoop或脱机数据仓库系统中以进行脱机处理和报告。
活动跟踪通常量很大,因为每个用户页面视图都会生成许多活动消息
1.3 监控指标
Kafka通常用于操作监控数据。这涉及汇总来自分布式应用程序的统计信息,以生成操作数据的集中。
1.4 日志汇总
许多人使用Kafka代替日志聚合解决方案。日志聚合通常从服务器收集物理日志文件,并将它们放在中央位置(也许是文件服务器或HDFS)以进行处理。Kafka提取文件的详细信息,并以日志流的形式更清晰地抽象日志或事件数据。这允许较低延迟的处理,并更容易支持多个数据源和分布式数据消耗。与以日志为中心的系统(例如Scribe或Flume)相比,Kafka具有同样出色的性能,由于复制而提供的更强的耐用性保证以及更低的端到端延迟。
1.5 流处理
Kafka的许多用户在由多个阶段组成的处理管道中处理数据,其中原始输入数据从Kafka主题中使用,然后进行汇总,充实或以其他方式转换为新主题,以供进一步使用或后续处理。例如,用于推荐新闻文章的处理管道可能会从RSS提要中检索文章内容,并将其发布到“文章”主题中。进一步的处理可能会使该内容规范化或重复数据删除,并将清洗后的文章内容发布到新主题中;最后的处理阶段可能会尝试向用户推荐此内容。这样的处理管道基于各个主题创建实时数据流的图形。从0.10.0.0开始,一个轻量但功能强大的流处理库称为Kafka Streams可以在Apache Kafka中使用来执行上述数据处理。除了Kafka Streams以外,其他开源流处理工具还包括Apache Storm和Apache Samza。
1.6 活动采集
事件源是一种应用程序,其中状态更改以时间顺序记录记录。Kafka对大量存储的日志数据的支持使其成为以这种样式构建的应用程序的绝佳后端。
1.7 提交日志
Kafka可以用作分布式系统的一种外部提交日志。该日志有助于在节点之间复制数据,并充当故障节点恢复其数据的重新同步机制。Kafka中的日志压缩功能有助于支持此用法。在这种用法中,Kafka类似于ApacheBookKeeper项目。
1.横向扩展,提高Kafka的处理能力
2.镜像,副本,提供高可用。
2. 集群搭建
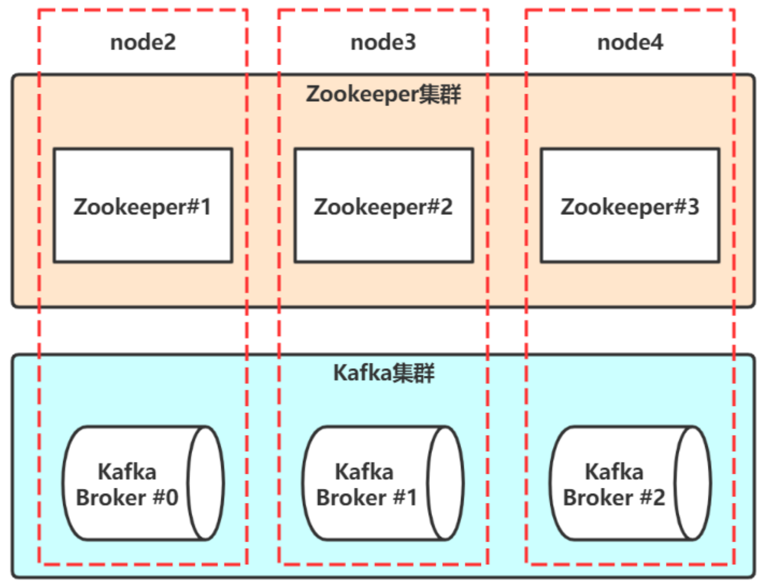
准备3台linux: qiang1, qiang2, qiang3
2.1 zookeeper集群安装
3台Linux都安装jdk
#解压.tar.gz包, 并配置环境变量 export JAVA_HOME=/usr/local/jdk1.8.0_261 export JRE_HOME=/usr/local/jdk1.8.0_261/jre export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib:$CLASSPATH export PATH=$JAVA_HOME/bin:$PATH安装zookeeper集群
wget https://dlcdn.apache.org/zookeeper/zookeeper-3.8.0/apache-zookeeper-3.8.0-bin.tar.gz #解压到/opt tar -zxvf apache-zookeeper-3.8.0-bin.tar.gz -C /opt #配置 cd /opt/apache-zookeeper-3.8.0-bin/conf cp zoo_sample.cfg zoo.cfg vim zoo.cfg #设置以下值 dataDir= /var/zookeeper/data #添加 server.1=qiang1:2881:3881 server.2=qiang2:2881:3881 server.3=qiang3:2881:3881 #创建以下目录 mkdir -p /var/zookeeper/data echo 1 > /var/zookeeper/data/myid #配置以下环境变量 export ZOOKEEPER_PREFIX=/opt/apache-zookeeper-3.8.0-bin export PATH=$PATH:$ZOOKEEPER_PREFIX/bin export ZOO_LOG_DIR=/var/zookeeper/log在3台linux启动zookeeper
zkServer.sh start #查看状态 zkServer.sh status
2.2 kafka集群安装
3台linux都安装
#下载
wget https://archive.apache.org/dist/kafka/1.0.0/kafka_2.12-1.0.0.tgz
#解压并配置环境变量
tar -zxvf kafka_2.12-1.0.0.tgz -C /opt/
export KAFKA_HOME=/opt/kafka_2.12-1.0.0
export PATH=$PATH:$KAFKA_HOME/bin
#kafka配置
vim /opt/kafka_2.12-1.0.0/config/server.properties
broker.id=0 #qiang1,qiang2,qiang3分别对应 0,1,2
listeners=PLAINTEXT://qiang1:9092 #配置内网地址 qiang1,qiang2,qiang3
advertised.listeners=PLAINTEXT://your.host.name:9092
log.dirs=/var/kafka-logs
zookeeper.connect=qiang1:2181,qiang2:2181,qiang3:2181/myKafka
#启动kafka
kafka-server-start.sh /opt/kafka_2.12-1.0.0/config/server.properties
或
kafka-server-start.sh -daemon /opt/kafka_2.12-1.0.0/config/server.properties
# 验证kafka: 启动时可看到分配 Cluster ID = DudFTUO-R0eyq2u-BPpGig
# 查看broker信息
zkCli.sh
get /myKafka/brokers/ids/0
get /myKafka/brokers/ids/1
get /myKafka/brokers/ids/2
3. 集群监控
Kafka使用Yammer Metrics在服务器和Scala客户端中报告指标。Java客户端使用KafkaMetrics,它是一个内置的度量标准注册表,可最大程度地减少拉入客户端应用程序的传递依赖项。两者都通过JMX公开指标,并且可以配置为使用可插拔的统计报告器报告统计信息,以连接到您的监视系统。
3.1 JMX
Kafka开启Jmx端口(3台linux都添加)
vim /opt/kafka_2.12-1.0.0/bin/kafka-server-start.sh export JMX_PORT=9581添加后重启
验证
如下图验证,即代表成功

3.2 使用console连接JMX端口
例mac电脑
- 命令行输入jconsole,即可打开(因为配置了java环境变量)
- ip:9581连接
3.3 编程实现监控
示例代码: jmxdemo