MapReduce编程框架
1. 思想
MapReduce思想在生活中处处可见。我们或多或少都曾接触过这种思想。MapReduce的思想核心是分而治之,充分利用了并行处理的优势。
即使是发布过论文实现分布式计算的谷歌也只是实现了这种思想,而不是自己原创。
MapReduce任务过程是分为两个处理阶段:
- Map阶段:Map阶段的主要作用是“分”,即把复杂的任务分解为若干个“简单的任务”来并行处理。Map阶段的这些任务可以并行计算,彼此间没有依赖关系。
- Reduce阶段:Reduce阶段的主要作用是“合”,即对map阶段的结果进行全局汇总。
2. 示例
序列化: Hadoop使用的是自己的序列化格式Writable,它比java的序列化serialization更紧凑速度更快。一个对象使用Serializable序列化后,会携带很多额外信息比如校验信息,Header,继承体系等。
Java基本类型与Hadoop常用序列化类型:

2.1 Mapper类
用户自定义一个Mapper类继承Hadoop的Mapper类
Mapper的输入数据是KV对的形式(类型可以自定义)
Map阶段的业务逻辑定义在map()方法中
Mapper的输出数据是KV对的形式(类型可以自定义)
注意:map()方法是对输入的一个KV对 调用一次!!
2.2 Reducer类
用户自定义Reducer类要继承Hadoop的Reducer类
Reducer的输入数据类型对应Mapper的输出数据类型(KV对)
Reducer的业务逻辑写在reduce()方法中
注意: Reduce()方法是对相同K的一组KV对 调用执行一次
2.3 Driver阶段
创建提交YARN集群运行的Job对象,其中封装了MapReduce程序运行所需要的相关参数入输入数据路径,输出数据路径等,也相当于是一个YARN集群的客户端,主要作用就是提交我们MapReduce程序运行。
2.4 示例代码
示例代码: https://gitee.com/ixinglan/map-reduce-demo.git
运行:
本地模式
直接Idea中运行驱动类即可, idea运行需要传入参数:

运行结束,去到输出结果路径查看结果
注意本地idea运行mr任务与集群没有任何关系,没有提交任务到yarn集群,是在本地使用多线程方式模拟的mr的运行
yarn集群模式
把程序打成jar包, 改名为wc.jar, 上传到hadoop集群
启动hadoop集群
使用hadoop命令提交任务运行
hadoop jar wc.jar com.example.mr.wc.WordcountDriver /***/input /***/output
3. 序列化Writable接口
基本序列化类型往往不能满足所有需求,比如在Hadoop框架内部传递一个自定义bean对象,那么该对象就需要实现Writable序列化接口
实现步骤:
必须实现Writable接口
反序列化时,需要反射调用空参构造函数,所以必须有空参构造
public CustomBean() { super(); }重写序列化方法
重写反序列化方法
反序列化的字段顺序和序列化字段的顺序必须完全一致
方便展示结果数据,需要重写bean对象的toString()方法,可以自定义分隔符
如果自定义Bean对象需要放在Mapper输出KV中的K,则该对象还需实现Comparable接口为因为MapReduce框中的Shuffle过程要求对key必须能排序!!
案例见示例代码: speak 统计每台智能音箱设备内容播放时长
原始日志文件:speak.data
001 001577c3 kar_890809 120.196.100.99 1116 954 200
日志id 设备id appkey(合作硬件厂商) 网络ip 自有内容时长(秒) 第三方内 容时长(秒) 网络状态码
# 结果
001577c3 11160 9540 20700
设备id 自有内容时长(秒) 第三方内容时长(秒) 总时长
4. MapReduce原理分析
4.1 运行机制详解
MapTask流程 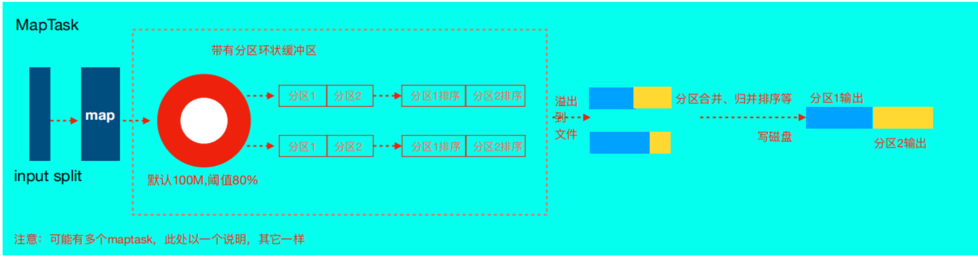
首先,读取数据组件InputFormat(默认TextInputFormat)会通过getSplits方法对输入’‘目录中’‘文件进行逻辑切片规划得到splits,有多少个split就对应启动多少个MapTask。split与block的对应关系默认是一对一。
将输入文件切分为splits之后,由RecordReader对象(默认LineRecordReader)进行读取,以\n作为分隔符,读取一行数据,返回<key,value>. key表示每行首字符偏移量,value表示这一行文本内容
读取split返回<key,value>,进入用户自己继承的mapper类中,执行用户重写的map函数.RecordReader读取一行这里调用一次
map逻辑完成之后,将map的每条结果通过context.write进行collect收集. 在collect中,会先对其进行分区处理,默认使用hashPartitioner.
MapReduce提供Partitioner接口,它的作用就是根据key或value及reduce的数量来决定当前的这对输出数据最终应该交由哪个reducetask处理。默认对keyhash后再以reducetask数量取模。默认的取模方式只是为了平均reduce的处理能力,如果用户自己对Partitioner有需求,可以订制并设置到job上。
接下来,会将数据写入内存,内存中这片区域叫做环形缓冲区,缓冲区的作用是批量收集map结果,减少磁盘IO的影响. 我们的key/value对 以及 partition的结果都会被写入缓冲区,当然写入之前,key与value值都会被序列化成字节数组.
- 环形缓冲区其实是一个数组,数组中存放着key、value的序列化数据和key、value的元数据信息,包括partition、key的起始位置、value的起始位置以及value的长度。环形结构是一个抽象概念。
- 缓冲区是有大小限制,默认是100MB。当map task的输出结果很多时,就可能会撑爆内存,所以需要在一定条件下将缓冲区中的数据临时写入磁盘,然后重新利用这块缓冲区。这个从内存往磁盘写数据的过程被称为Spill,中文可译为溢写。这个溢写是由单独线程来完成,不影响往缓冲区写map结果的线程。溢写线程启动时不应该阻止map的结果输出,所以整个缓冲区有个溢写的比例spill.percent。这个比例默认是0.8,也就是当缓冲区的数据已经达到阈值(buffersizespill percent=100MB0.8=80MB),溢写线程启动,锁定这80MB的内存,执行溢写过程。Map task的输出结果还可以往剩下的20MB内存中写,互不影响。
当溢写线程启动后,需要对这80MB空间内的key做排序(Sort)。排序是MapReduce模型默认的行为!
- 如果job设置过Combiner,那么现在就是使用Combiner的时候了。将有相同key的key/value对的value加起来,减少溢写到磁盘的数据量。Combiner会优化MapReduce的中间结果,所以它在整个模型中会多次使用。
- 那哪些场景才能使用Combiner呢?从这里分析,Combiner的输出是Reducer的输入,Combiner 绝不能改变最终的计算结果。Combiner只应该用于那种Reduce的输入key/value与输出key/value 类型完全一致,且不影响最终结果的场景。比如累加,最大值等。Combiner的使用一定得慎重,如果用好,它对job执行效率有帮助,反之会影响reduce的最终结果。
合并溢写文件:每次溢写会在磁盘上生成一个临时文件(写之前判断是否有combiner),如果map的输出结果真的很大,有多次这样的溢写发生,磁盘上相应的就会有多个临时文件存在。当整个数据处理结束之后开始对磁盘中的临时文件进行merge合并,因为最终的文件只有一个,写入磁盘,并且为这个文件提供了一个索引文件,以记录每个reduce对应数据的偏移量。
4.2 MapTask并行度
MapTask的并行度决定Map阶段的任务处理并发度,从而影响到整个Job的处理速度
MapTask并行度决定机制:
- 数据块:Block是HDFS物理上把数据分成一块一块 默认128M
- 切片:数据切片只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储。
如果一个文件仅仅比128M大一点点也被当成一个split来对待,而不是多个split.
MR框架在并行运算的同时也会消耗更多资源,并行度越高资源消耗也越高
4.3 ReduceTask工作机制
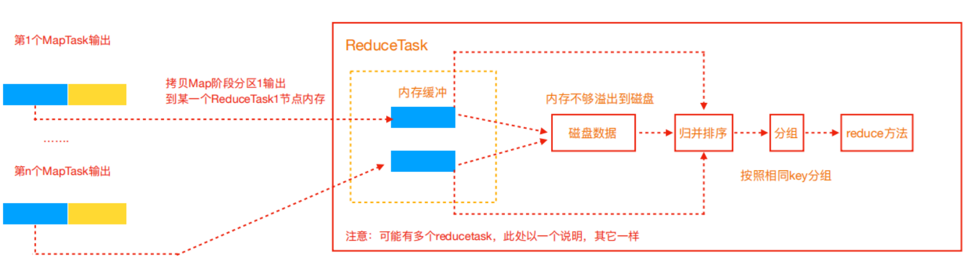
Reduce大致分为copy、sort、reduce三个阶段,重点在前两个阶段。copy阶段包含一个eventFetcher来获取已完成的map列表,由Fetcher线程去copy数据,在此过程中会启动两个merge线程,分别为inMemoryMerger和onDiskMerger,分别将内存中的数据merge到磁盘和将磁盘中的数据进行merge。待数据copy完成之后,copy阶段就完成了,开始进行sort阶段,sort阶段主要是执行 finalMerge操作,纯粹的sort阶段,完成之后就是reduce阶段,调用用户定义的reduce函数进行处理。
Copy阶段
简单地拉取数据。Reduce进程启动一些数据copy线程(Fetcher),通过HTTP方式请求maptask获取属于自己的文件。
Merge阶段。
这里的merge如map端的merge动作,只是数组中存放的是不同map端copy来的数值。Copy过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比map端的更为灵活。merge 有三种形式:内存到内存;内存到磁盘;磁盘到磁盘。默认情况下第一种形式不启用。当内存中的数据量到达一定阈值,就启动内存到磁盘的merge。与map端类似,这也是溢写的过程,这个过程中如果你设置有Combiner,也是会启用的,然后在磁盘中生成了众多的溢写文件。第二种 merge方式一直在运行,直到没有map端的数据时才结束,然后启动第三种磁盘到磁盘的merge 方式生成最终的文件。
合并排序
把分散的数据合并成一个大的数据后,还会再对合并后的数据排序。
对排序后的键值对调用reduce方法,键相等的键值对调用一次reduce方法,每次调用会产生零个或者多个键值对,最后把这些输出的键值对写入到HDFS文件中。
4.4 ReduceTask并行度
ReduceTask的并行度同样影响整个Job的执行并发度和执行效率,但与MapTask的并发数由切片数决定不同,ReduceTask数量的决定是可以直接手动设置:
job.setNumReduceTasks(4);//默认是1
- ReduceTask=0,表示没有Reduce阶段,输出文件数和MapTask数量保持一致;
- ReduceTask数量不设置默认就是一个,输出文件数量为1个;
- 如果数据分布不均匀,可能在Reduce阶段产生倾斜;
4.5 shuffle机制
map阶段处理的数据如何传递给reduce阶段,是MapReduce框架中最关键的一个流程,这个流程就叫shuffle。
shuffle:洗牌、发牌——(核心机制:数据分区,排序,分组,combine,合并等过程)
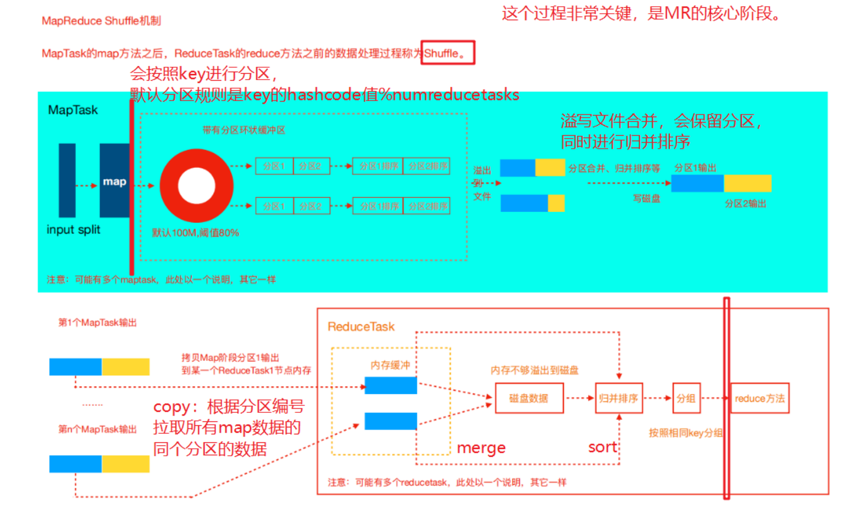
MapReduce的分区与reduceTask的数量
在MapReduce中,通过我们指定分区,会将同一个分区的数据发送到同一个reduce当中进行处理(默认是key相同去往同个分区).
MR程序shuffle机制默认就是这种规则
翻阅源码验证以上规则,MR程序默认使用的HashPartitioner,保证了相同的key去往同个分区!!
自定义分区
- 自定义类继承Partitioner,重写getPartition()方法
- 在Driver驱动中,指定使用自定义Partitioner
- 在Driver驱动中,要根据自定义Partitioner的逻辑设置相应数量的ReduceTask数量。
需求: 按照不同的appkey把记录输出到不同的分区中
见示例代码: partition
Tips:
自定义分区器时最好保证分区数量与reduceTask数量保持一致;
如果分区数量不止1个,但是reduceTask数量1个,此时只会输出一个文件。
如果reduceTask数量大于分区数量,但是输出多个空文件
如果reduceTask数量小于分区数量,有可能会报错。
MapReduce中的Combiner
combiner支行机制:
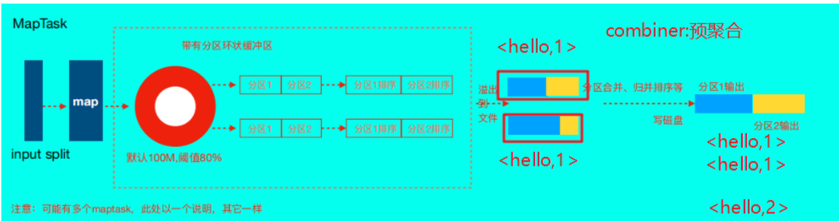
- Combiner是MR程序中Mapper和Reducer之外的一种组件
- Combiner组件的父类就是Reducer
- Combiner和reducer的区别在于运行的位置
- .Combiner是在每一个maptask所在的节点运行;
- Combiner的意义就是对每一个maptask的输出进行局部汇总,以减小网络传输量。
- Combiner能够应用的前提是不能影响最终的业务逻辑,此外,Combiner的输出kv应该跟reducer
自定义combiner: 见代码示例 wc
4.6 MapReduce中的排序
排序是MapReduce框架中最重要的操作之一。
MapTask和ReduceTask均会对数据按照key进行排序。该操作属于Hadoop的默认行为。任何应用程序中的数据均会被排序,而不管逻辑上是否需要。默认排序是按照字典顺序排序,且实现该排序的方法是快速排序。
- MapTask
- 它会将处理的结果暂时放到环形缓冲区中,当环形缓冲区使用率达到一定阈值后,再对缓冲区中的数据进行一次快速排序,并将这些有序数据溢写到磁盘上,
- 溢写完毕后,它会对磁盘上所有文件进行归并排序。
- ReduceTask当所有数据拷贝完毕后,ReduceTask统-对内存和磁盘上的所有数据进行一次归并排序。
部分排序.
MapReduce根据输入记录的键对数据集排序。保证输出的每个文件内部有序。
全排序
最终输出结果只有一个文件,且文件内部有序。实现方式是只设置- -个ReduceTask。但该方法在处理大型文件时效率极低,因为- -台机器处理所有文件,完全丧失了MapReduce所提供的并行架构。
辅助排序: ( GroupingComparator分组)
在Reduce端对key进行分组。应用于:在接收的key为bean对象时,想让一个或几个字段相同(全部字段比较不相同)的key进入到同一个reduce方法时,可以采用分组排序。
二次排序.
在自定义排序过程中,如果compareTo中的判断条件为两个即为二次排序。
WritableComparable
Bean对象如果作为Map输出的key时,需要实现WritableComparable接口并重写compareTo方法指定排序规则
全排序: 基于统计的播放时长案例的输出结果对总时长进行排序, 实现全局排序只能设置一个ReduceTask!
见示例代码: sort
分区排序: 默认
GroupingComparator
GroupingComparator是mapreduce当中reduce端的一个功能组件,主要的作用是决定哪些数据作为一组,调用一次reduce的逻辑,默认是每个不同的key,作为多个不同的组,每个组调用一次reduce逻辑,我们可以自定义GroupingComparator实现不同的key作为同一个组,调用一次reduce逻辑。
见示例代码: group
4.7 MapReduce读取和输出数据
InputFormat
运行MapReduce程序时,输入的文件格式包括:基于行的日志文件、二进制格式文件、数据库表等。那么,针对不同的数据类型,MapReduce是如何读取这些数据的呢?
InputFormat是MapReduce框架用来读取数据的类。
InputFormat常见子类包括:
- TextInputFormat(普通文本文件,MR框架默认的读取实现类型)
- KeyValueTextInputFormat(读取一行文本数据按照指定分隔符,把数据封装为kv类型)NLineInputFormat(读取数据按照行数进行划分分片)
- CombineTextInputFormat(合并小文件,避免启动过多MapTask任务)
- 自定义InputFormat
// 案例 MR框架默认的TextInputFormat切片机制按文件划分切片, 文件无论多小,都是单独一个切片,然后由一个MapTask处理, 如果有大量小文件,就对应的会生成并启动大量的MapTask, 而每个MapTask处理的数据量很小大量时间浪费在初始化资源 启动收回等阶段,这种方式导致资源利用率不高。 CombineTextInputFormat用于小文件过多的场景, 它可以将多个小文件从逻辑上划分成一个切片,这样 多个小文件就可以交给一个MapTask处理,提高资源利用率。 需求: 将输入数据中的多个小文件合并为一个切片处理 // 如果不设置InputFormat,它默认用的是TextInputFormat.class job.setInputFormatClass(CombineTextInputFormat.class); //虚拟存储切片最大值设置4m CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);CombineTextInputFormat切片原理:
切片生成过程分为两部分:虚拟存储过程和切片过程, 假设设置setMaxInputSplitSize值为4M
四个小文件:1.txt –>2M ;2.txt–>7M;3.txt–>0.3M;4.txt—>8.2M
虚拟存储过程:把输入目录下所有文件大小,依次和设置的setMaxInputSplitSize值进行比较,如果不大于设置的最大值,逻辑上划分一个块。如果输入文件大于设置的最大值且大于两倍,那么以最大值切割一块;当剩余数据大小超过设置的最大值且不大于最大值2倍,此时将文件均分成2个虚拟存储块(防止出现太小切片)。
比如如setMaxInputSplitSize值为4M,输入文件大小为8.02M,则先逻辑上分出一个4M的块。剩余的大小为4.02M,如果按照4M逻辑划分,就会出现0.02M的非常小的虚拟存储文件,所以将剩余的4.02M文件切分成(2.01M和2.01M)两个文件。
1.txt–>2M;2M<4M;一个块;
2.txt–>7M;7M>4M,但是不大于两倍,均匀分成两块;两块:每块3.5M;
3.txt–>0.3M;0.3<4M,一个块
4.txt–>8.2M;大于最大值且大于两倍;一个4M的块,剩余4.2M分成两块,每块2.1M 所有块信息:2M,3.5M,3.5M,0.3M,4M,2.1M,2.1M共7个虚拟存储块。
切片过程
判断虚拟存储的文件大小是否大于setMaxInputSplitSize值,大于等于则单独形成一个切片。
如果不大于则跟下一个虚拟存储文件进行合并,共同形成一个切片。
按照之前输入文件:有4个小文件大小分别为2M、7M、0.3M以及8.2M这四个小文件,则虚拟存储之后形成7个文件块,大小分别为:2M,3.5M,3.5M,0.3M,4M,2.1M,2.1M
自定义InputFormat见示例代码: sequence
OutputFormat
OutputFormat:是MapReduce输出数据的基类,所有MapReduce的数据输出都实现了OutputFormat 抽象类。下面我们介绍几种常见的OutputFormat子类
TextOutputFormat
默认的输出格式是TextOutputFormat,它把每条记录写为文本行。它的键和值可以是任意类型,因为TextOutputFormat调用toString()方法把它们转换为字符串。
SequenceFileOutputFormat
将SequenceFileOutputFormat输出作为后续MapReduce任务的输入,这是一种好的输出格式,因为它的格式紧凑,很容易被压缩。
自定义OutputFormat见示例代码: output
4.8 shuffle阶段数据的压缩机制
压缩算法
数据压缩有两大好处,节约磁盘空间,加速数据在网络和磁盘上的传输!!
我们可以使用bin/hadoop check native来查看我们编译之后的hadoop支持的各种压缩,如果出现openssl为false,那么就在线安装 一下依赖包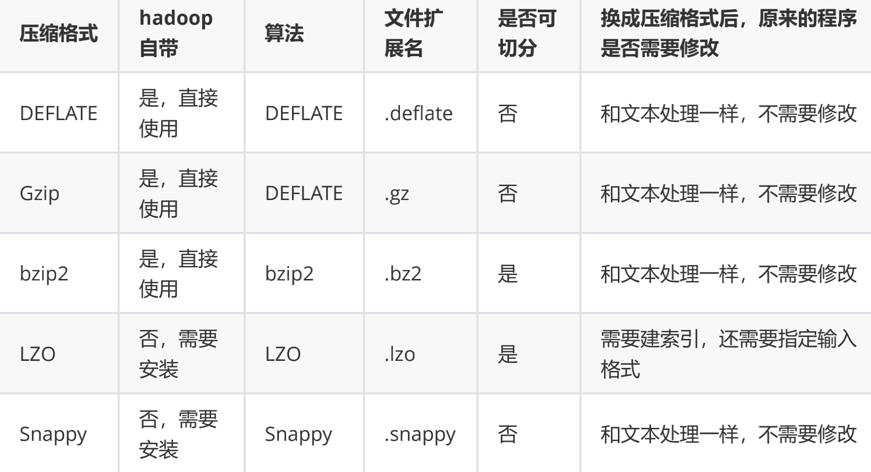
为了支持多种压缩/解压缩算法,Hadoop引入了编码/解码器
| 压缩格式 | 对应编码/解码器 |
|---|---|
| DEFLATE | org.apache.hadoop.io.compress.DefaultCodec |
| gzip | org.apache.hadoop.io.compress.GzipCodec |
| Bzip2 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | com.hadoop.compression.lzo.LzopCodec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
各压缩算法对比: 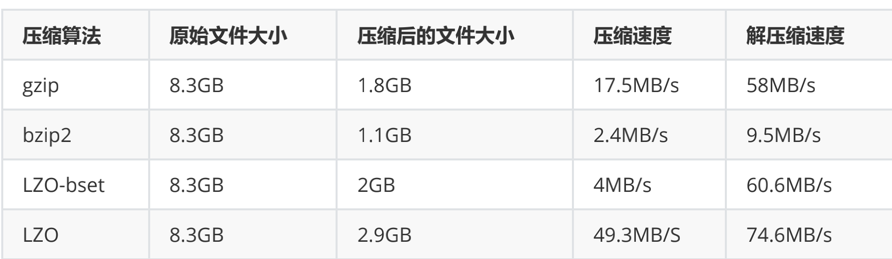
压缩位置
map输入端压缩
此处使用压缩文件作为Map的输入数据,无需显示指定编解码方式,Hadoop会自动检查文件扩展名,如果压缩方式能够匹配,Hadoop就会选择合适的编解码方式对文件进行压缩和解压
map输出端压缩
Shuffle是HadoopMR过程中资源消耗最多的阶段,如果有数据量过大造成网络传输速度缓慢,可以考虑使用压缩
Reduce端输出压缩
输出的结果数据使用压缩能够减少存储的数据量,降低所需磁盘的空间,并且作为第二个MR的输入时可以复用压缩
压缩配置方式
在驱动代码中通过Configuration直接设置使用的压缩方式,可以开启Map输出和Reduce输出压缩
设置map阶段压缩 Configurationconfiguration=newConfiguration(); configuration.set("mapreduce.map.output.compress","true"); configuration.set("mapreduce.map.output.compress.codec","org.apache.hadoop.i o.compress.SnappyCodec"); 设置reduce阶段的压缩 configuration.set("mapreduce.output.fileoutputformat.compress","true"); configuration.set("mapreduce.output.fileoutputformat.compress.type","RECORD"); configuration.set("mapreduce.output.fileoutputformat.compress.codec","org.apache.hadoop.io.compress.SnappyCodec");配置mapred-site.xml(修改后分发到集群其它节点,重启Hadoop集群),此种方式对运行在集群的所有MR任务都会执行压缩
<property> <name>mapreduce.output.fileoutputformat.compress</name> <value>true</value> </property> <property> <name>mapreduce.output.fileoutputformat.compress.type</name> <value>RECORD</value> </property> <property> <name>mapreduce.output.fileoutputformat.compress.codec</name> <value>org.apache.hadoop.io.compress.SnappyCodec</value> </property>