Elasticsearch入门使用
Elasticsearch是基于Lucene的全文检索引擎,本质也是存储和检索数据。ES中的很多概念与MySQL类 似 我们可以按照关系型数据库的经验去理解。
1. 核心概念
索引(index)
类似的数据放在一个索引,非类似的数据放不同索引, 一个索引也可以理解成一个关系型数据库
类型(type)
代表document属于index中的哪个类别(type)也有一种说法一种type就像是数据库的表,比如dept表,user表
注意ES每个大版本之间区别很大: ES 5.x中一个index可以有多种type。 ES 6.x中一个index只能有一种type。 ES 7.x以后 要逐渐移除type这个概念。映射(mapping)
mapping定义了每个字段的类型等信息。相当于关系型数据库中的表结构
常用数据类型:text、keyword、number、array、range、boolean、date、geo_point、ip、nested、object
2. API介绍
Elasticsearch提供了Rest风格的API,即http请求接口,而且也提供了各种语言的客户端API。
rest风格API
文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
客户端API
Elasticsearch支持的语言客户端非常多:https://www.elastic.co/guide/en/elasticsearch/client/index.html
ElasticSearch没有自带图形化界面,我们可以通过安装ElasticSearch的图形化插件,完成图形化界面的效果,完成索引数据的查看,比如可视化插件Kibana
3. 安装配置kibana
Kibana是一个基于Node.js的Elasticsearch索引库数据统计工具,可以利用Elasticsearch的聚合功能,生成各种图表,如柱形图,线状图,饼图等。
而且还提供了操作Elasticsearch索引数据的控制台,并且提供了一定的API提示,非常有利于我们学习Elasticsearch的语法
root账户下操作
#1.下载Kibana,下载与es对应版本
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.8.0-linux-x86_64.tar.gz
#2.解压并放到安装目录
tar -zxvf kibana-7.8.0-linux-x86_64.tar.gz -C /usr/local/kibana
#3.改变es目录拥有者账号,并设置访问权限
chown -R estest /usr/local/kibana/
chmod -R 777 /usr/local/kibana/
#4.修改配置文件 kibana/config/kibana.yml
#修改端口,访问ip,elasticsearch服务器ip
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://ip:9200"]
#5.配置完启动
su estest
./bin/kibana #kibana下bin目录
不报错即启动成功,通过 http://ip:5601访问
tips: 占用内存大,机器内存不大的话,建议分两台机器安装
控制台页面如下:
tips: 快捷键
ctrl+enter 提交请求
ctrl+i 自动缩进
4. 集成IK分词器
IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始,IKAnalyzer已经推出 了3个大版本。最初,它是以开源项目Lucene为应用主体的,结合词典分词和文法分析算法的中文分词组件。新版本的IKAnalyzer3.0则发展为 面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。
IK分词器3.0的特性如下:
1)采用了特有的“正向迭代最细粒度切分算法“,具有60万字/秒的高速处理能力。
2)采用了多子处理器分析模式,支持:英文字母(IP地址、Email、URL)、数字(日期,常用中文数
量词,罗马数字,科学计数法),中文词汇(姓名、地名处理)等分词处理。
3)支持个人词条的优化的词典存储,更小的内存占用。
4)支持用户词典扩展定义。
5)针对Lucene全文检索优化的查询分析器IKQueryParser;采用歧义分析算法优化查询关键字的搜索
排列组合,能极大的提高Lucene检索的命中率。
下载地址:
https://github.com/medcl/elasticsearch-analysis-ik/releases
4.1 安装IK分词器
方式一:
在elasticsearch的bin目录下执行以下命令,es插件管理器会自动帮我们安装,然后等待安装完成
安装对应版本
/elasticsearch/bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.8.0/elasticsearch-analysis-ik-7.8.0.zip下载完成后会提示 Continue with installation?输入 y 即可完成安装
重启Elasticsearch 和Kibana
方式二:
在elasticsearch安装目录的plugins目录下新建 analysis-ik 目录
#新建analysis-ik文件夹 mkdir analysis-ik #切换至 analysis-ik文件夹下 cd analysis-ik #上传资料中的 elasticsearch-analysis-ik-7.8.0.zip #解压 unzip elasticsearch-analysis-ik-7.8.0.zip #解压完成后删除zip rm -rf elasticsearch-analysis-ik-7.8.0.zip重启es和kibana
测试数据:
IK分词器有两种分词模式 ik_max_word(常用会将文本做最细粒度的拆分)和ik_smart(会做最粗粒度的拆分)模式
下面使用kibana发送请求测试
POST _analyze
{
"analyzer": "ik_max_word",
"text": "南京市长江大桥"
}
ik_max_word 分词模式运行得到结果:
{
"tokens" : [
{
"token" : "南京市",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "南京",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "市长",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "长江大桥",
"start_offset" : 3,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "长江",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "大桥",
"start_offset" : 5,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 5
}
]
}
ik_smart分词模式运行得到结果:
POST _analyze
{
"analyzer": "ik_smart",
"text": "南京市长江大桥"
}
ik_smart分词模式运行得到结果:
{
"tokens" : [
{
"token" : "南京市",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "长江大桥",
"start_offset" : 3,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 1
}
]
}
4.2 扩展词典使用
扩展词:就是不想让哪些词被分开,让他们分成一个词。比如上面的江大桥
自定义扩展词库方法:
进入到 confifig/analysis-ik/(插件命令安装方式) 或 plugins/analysis-ik/confifig(安装包安装方式) 目录下, 新增自定义词典
#如 my_custom_ext_dict.dic vim my_custom_ext_dict.dic 输入: 江大桥将我们自定义的扩展词典文件添加到IKAnalyzer.cfg.xml配置中
vim IKAnalyzer.cfg.xml<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict">my_custom_ext_dict.dic</entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords">my_custom_stop_dict.dic</entry> <!--用户可以在这里配置远程扩展字典 --> <!-- <entry key="remote_ext_dict">http://192.168.211.130:8080/tag.dic</entry> --> <!--用户可以在这里配置远程扩展停止词字典--> <!-- <entry key="remote_ext_stopwords">words_location</entry> --> </properties>重启es
4.3 信用词典使用
停用词:有些词在文本中出现的频率非常高。但对本文的语义产生不了多大的影响。例如英文的a、an、the、of等。或中文的”的、了、呢等”。这样的词称为停用词。停用词经常被过滤掉,不会被进行索引。在检索的过程中,如果用户的查询词中含有停用词,系统会自动过滤掉。停用词可以加快索引的速度,减少索引库文件的大小。
自定义停用词方法:
进入到 confifig/analysis-ik/(插件命令安装方式) 或 plugins/analysis-ik/confifig(安装包安装方式) 目录下, 新增自定义词典
vim my_custom_stop_dict.dic 的 了 啊将我们自定义的停用词典文件添加到IKAnalyzer.cfg.xml配置中
重启es
4.4 同义词典使用
语言博大精深,有很多相同意思的词,我们称之为同义词,比如“番茄”和“西红柿”,“馒头”和“馍”等。在搜索的时候,我们输入的可能是“番茄”,但是应该把含有“西红柿”的数据一起查询出来,这种情况叫做同义词查询
注意:扩展词和停用词是在索引的时候使用,而同义词是检索时候使用。
配置IK同义词
Elasticsearch 自带一个名为 synonym 的同义词 fifilter。为了能让 IK 和 synonym 同时工作,我们需要定义新的 analyzer,用 IK 做 tokenizer,synonym 做 filter。听上去很复杂,实际上要做的只是加一段配置。
创建/config/analysis-ik/synonym.txt 文件,输入一些同义词并存为 utf-8 格式。
例如: tomato,西红柿 china,中国创建索引时,使用同义词配置,示例模板如下
PUT /索引名称 { "settings":{ "analysis":{ "filter":{ "word_sync":{ "type":"synonym", "synonyms_path":"analysis-ik/synonym.txt" } }, "analyzer":{ "ik_sync_max_word":{ "filter":[ "word_sync" ], "type":"custom", "tokenizer":"ik_max_word" }, "ik_sync_smart":{ "filter":[ "word_sync" ], "type":"custom", "tokenizer":"ik_smart" } } } }, "mappings":{ "properties":{ "字段名":{ "type":"字段类型", "analyzer":"ik_sync_smart", "search_analyzer":"ik_sync_smart" } } } }以上配置定义了ik_sync_max_word和ik_sync_smart这两个新的 analyzer,对应 IK 的 ik_max_word 和ik_smart 两种分词策略。ik_sync_max_word和 ik_sync_smart都会使用 synonym fifilter 实现同义词转换
到此,索引创建模板中同义词配置完成,搜索时指定分词为ik_sync_max_word或ik_sync_smart
案例
PUT /qiang-es-synonym { "settings":{ "analysis":{ "filter":{ "word_sync":{ "type":"synonym", "synonyms_path":"analysis-ik/synonym.txt" } }, "analyzer":{ "ik_sync_max_word":{ "filter":[ "word_sync" ], "type":"custom", "tokenizer":"ik_max_word" }, "ik_sync_smart":{ "filter":[ "word_sync" ], "type":"custom", "tokenizer":"ik_smart" } } } }, "mappings":{ "properties":{ "name":{ "type":"text", "analyzer":"ik_sync_max_word", "search_analyzer":"ik_sync_max_word" } } } }插入数据:
POST /qiang-es-synonym/_doc/1 { "name":"我是中国人,我爱吃土豆和西红柿炒鸡蛋" }使用同义词进行搜索:
POST /qiang-es-synonym/_doc/_search { "query":{ "match":{ "name":"china" } } }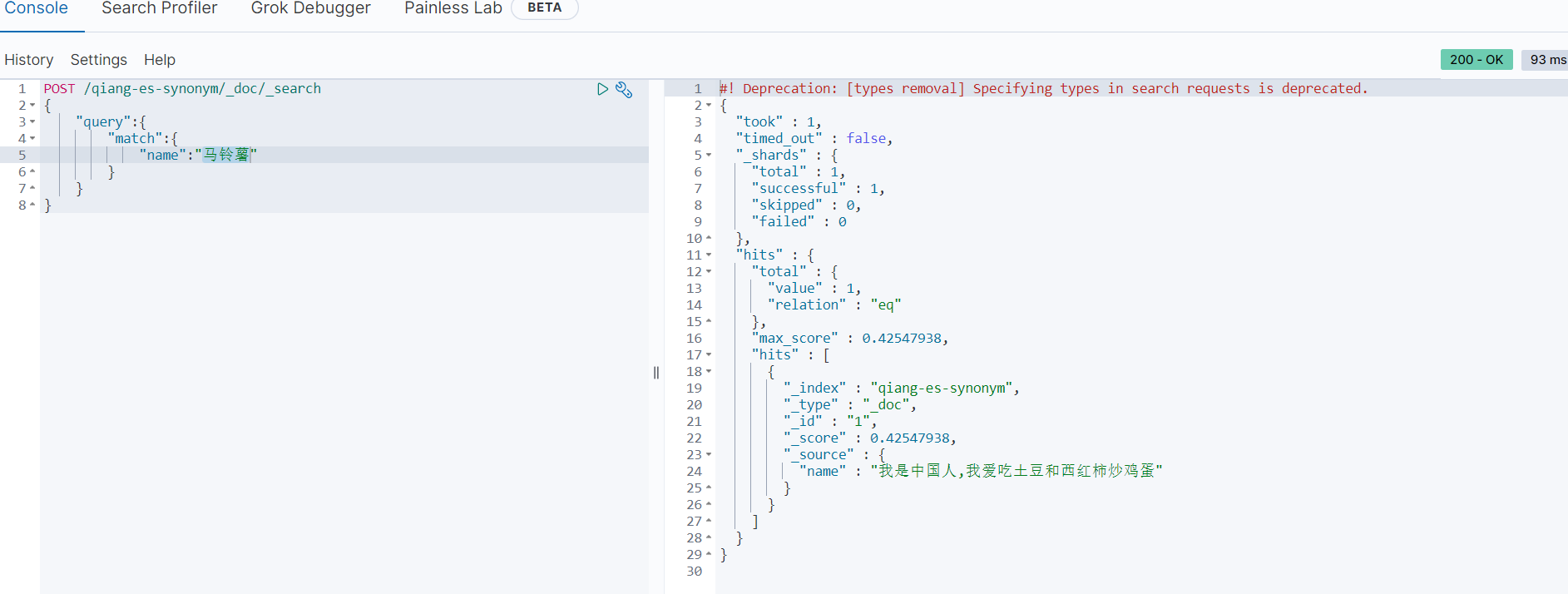
5. 索引操作(创建,查看,删除)
5.1 创建索引库
PUT /索引名称
{
"settings":{
"属性名":"属性值"
}
}
settings:就是索引库设置,其中可以定义索引库的各种属性 比如分片数 副本数等,目前我们可以不
设置,都走默认

5.2 判断索引是否存在
HEAD /索引名称
5.3 查看索引
GET /qiang-es-demo1
批量查看索引:
GET /索引名称1,索引名称2,索引名称3,...
查看所有索引:
GET _all
或
GET /_cat/indices?v
绿色:索引的所有分片都正常分配。
黄色:至少有一个副本没有得到正确的分配。
红色:至少有一个主分片没有得到正确的分配。
5.4 打开索引
POST /索引名称/_open
5.5 关闭索引
POST /索引名称/_close
5.6 删除索引
DELETE /索引名称1,索引名称2,索引名称3...
6.映射操作
索引创建之后,等于有了关系型数据库中的database。Elasticsearch7.x取消了索引type类型的设置,不允许指定类型,默认为_doc,但字段仍然是有的,我们需要设置字段的约束信息,叫做字段映射(mapping)
字段的约束包括但不限于:
1.字段的数据类型
2.是否要存储
3.是否要索引
4.分词器
6.1 创建映射字段
PUT /索引库名/_mapping
{
"properties":{
"字段名":{
"type":"类型",
"index":true,
"store":true,
"analyzer":"分词器"
}
}
}
字段名:任意填写,下面指定许多属性,例如:
type:类型,可以是text、long、short、date、integer、object等
index:是否索引,默认为true
store:是否存储,默认为false
analyzer:指定分词器
示例:
PUT /qiang-es-demo1/_mapping/
{
"properties":{
"name":{
"type":"text",
"analyzer":"ik_max_word"
},
"job":{
"type":"text",
"analyzer":"ik_max_word"
},
"logo":{
"type":"keyword",
"index":"false"
},
"payment":{
"type":"float"
}
}
}
6.2 映射属性详解
type
官方文档:
https://www.elastic.co/guide/en/elasticsearch/reference/7.3/mapping-types.html此处介绍几个关键的:
String,又分两种
text: 可分词,不可参与聚合 keyword:不可分词,数据会作为完整字段进行匹配,可以参与聚合Numerical:数值类型,分两类
基本数据类型:long、interger、short、byte、double、float、half_float 浮点数的高精度类型:scaled_float, 需要指定一个精度因子,比如10或100。elasticsearch会把真实值乘以这个因子后存储,取出时再还原Date: 日期类型
elasticsearch可以对日期格式化为字符串存储,但是建议我们存储为毫秒值,存储为long,节省空间。
Array:数组类型
进行匹配时,任意一个元素满足,都认为满足 排序时,如果升序则用数组中的最小值来排序,如果降序则用数组中的最大值来排序Object: 对象
{ "name":"Jack", "age":21, "girl":{ "name":"Rose", "age":21 } } #如果存储到索引库的是对象类型,例如上面的girl,会把girl变成两个字段:girl.name和girl.age
index
index影响字段的索引情况。
true:字段会被索引,则可以用来进行搜索。默认值就是true false:字段不会被索引,不能用来搜索store
是否将数据进行独立存储。
原始的文本会存储在 _source 里面,默认情况下其他提取出来的字段都不是独立存储的,是从_source 里面提取出来的。当然你也可以独立的存储某个字段,只要设置store:true即可,获取独立存储的字段要比从**_source**中解析快得多,但是也会占用更多的空间,所以要根据实际业务需求来设置,默认为false
analyzer:指定分词器
一般我们处理中文会选择ik分词器 ik_max_word ik_smart
6.3 查看映射关系
查看单个索引映射关系
GET /索引名称/_mapping查看所有索引 映射关系
GET _mapping 或 GET _all/_mapping修改索引映射关系
PUT /索引库名/_mapping { "properties":{ "字段名":{ "type":"类型", "index":true, "store":true, "analyzer":"分词器" } } }注意:修改映射增加字段 做其它更改只能删除索引 重新建立映射
6.4 一次性创建索引和映射
put /索引库名称
{
"settings":{
"索引库属性名":"索引库属性值"
},
"mappings":{
"properties":{
"字段名":{
"映射属性名":"映射属性值"
}
}
}
}
7. 文档增删改查及局部更新
文档,即索引库中的数据,会根据规则创建索引,将来用于搜索。可以类比做数据库中的一行数据。
7.1 新增文档
新增文档时,涉及到id的创建方式,手动指定或者自动生成。
新增文档(手动指定id)
POST /索引名称/_doc/{id}示例:
POST /qiang-es-demo1/_doc/1 { "name":"百度", "job":"小度用户运营经理", "payment":"30000", "logo":"http://www.lgstatic.com/thubnail_120x120/i/image/M00/21/3E/CgpFT1kVdzeAJNbU AABJB7x9sm8374.png" }新增文档(自动生成id)
POST /索引名称/_doc { "field":"value" }示例:
POST /qiang-es-demo1/_doc { "name":"百度", "job":"小度用户运营经理", "payment":"30000", "logo":"http://www.lgstatic.com/thubnail_120x120/i/image/M00/21/3E/CgpFT1kVdzeAJNbU AABJB7x9sm8374.png" }
7.2 查看单个文档
GET /索引名称/_doc/{id}
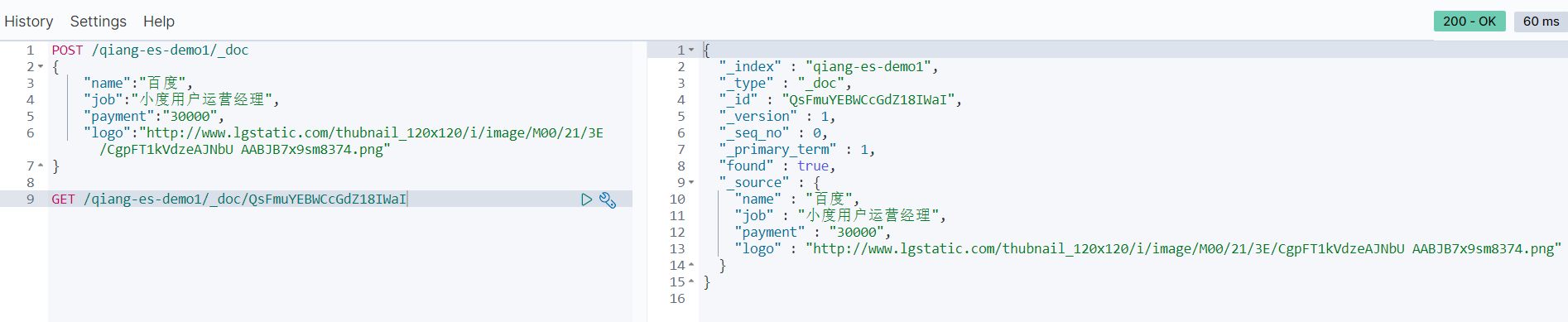
| 元数据项 | 含义 |
|---|---|
| _index | document所属index |
| _type | document所属type,Elasticsearch7.x默认type为_doc |
| _id | 代表document的唯一标识,与index和type一起,可以唯一标识和定位一个document |
| _version | document的版本号,Elasticsearch利用_version (版本号)的方式来确保应用中相互冲突的变更不会导致数据丢失。需要修改数据时,需要指定想要修改文档的version号,如果该版本不是当前版本号,请求将会失败 |
| _seq_no | 严格递增的顺序号,每个文档一个,Shard级别严格递增,保证后写入的Doc seq_no大于先写入的Doc的seq_no, 任何类型的写操作,包括index、create、update和Delete,都会生成一个_seq_no |
| _primary_term | primary_term也和_seq_no一样是一个整数,每当Primary Shard发生重新分配时,比如重启,Primary选举等,_primary_term会递增1 |
| found | true/false,是否查找到文档 |
| _source | 存储原始文档 |
7.3 查看所有文档
POST /索引名称/_search
{
"query":{
"match_all":{
}
}
}
7.4 _source定制返回结果
某些业务场景下,我们不需要搜索引擎返回source中的所有字段,可以使用source进行定制,如下,多个字段之间使用逗号分隔
GET /qiang-es-demo1/_doc/1?_source=name,job
7.5 更新文档(全部更新)
把刚才新增的请求方式改为PUT,就是修改了,不过修改必须指定id: id对应文档存在则修改,不存在则新增
7.6 更新文档(局部更新)
Elasticsearch可以使用PUT或者POST对文档进行更新(全部更新),如果指定ID的文档已经存在,则执行更新操作
**注意:**Elasticsearch执行更新操作的时候,Elasticsearch首先将旧的文档标记为删除状态,然后添加新的文档,旧的文档不会立即消失,但是你也无法访问,Elasticsearch会在你继续添加更多数据的时候在后台清理已经标记为删除状态的文档。
全部更新,是直接把之前的老数据,标记为删除状态,然后,再添加一条更新的(使用PUT或者POST)
局域更新,只是修改某个字段(使用POST)
POST /索引名/_update/{id}
{
"doc":{
"field":"value"
}
}
7.7 删除文档
根据id删除
DELETE /索引名/_doc/{id}根据查询条件进行删除
POST /索引库名/_delete_by_query { "query":{ "match":{ "字段名":"搜索关键字" } } }
7.8 文档的全量替换,强制创建
全量替换
- 语法与创建文档是一样的,如果文档id不存在,那么就是创建;如果文档id已经存在,那么就是全量替换操作,替换文档的json串内容;
- 文档是不可变的,如果要修改文档的内容,第一种方式就是全量替换,直接对文档重新建立索引,替换里面所有的内容,elasticsearch会将老的文档标记为deleted,然后新增我们给定的一个文档,当我们创建越来越多的文档的时候,elasticsearch会在适当的时机在后台自动删除标记为deleted的文档
强制创建
PUT /index/_doc/{id}?op_type=create {} PUT /index/_doc/{id}/_create {}如果id 存在就会报错