分布式id解决方案
例:分表之后,不用主键自增,采用分布式id方案
UUID
UUID 是指Universally Unique Identifier,翻译为中⽂是通⽤唯⼀识别码
产⽣重复 UUID 并造成错误的情况⾮常低,是故⼤可不必考虑此问题。
Java中得到⼀个UUID,可以使⽤java.util包提供的⽅法
独立数据库的自增id
⽐如A表分表为A1表和A2表,那么肯定不能让A1表和A2表的ID⾃增,那么ID怎么获取呢?我们可以单独的创建⼀个Mysql数据库,在这个数据库中创建⼀张表,这张表的ID设置为⾃增,其他地⽅需要全局唯⼀ID的时候,就模拟向这个Mysql数据库的这张表中模拟插⼊⼀条记录,此时ID会⾃增,然后我们可以通过Mysql的select last_insert_id() 获取到刚刚这张表中⾃增⽣成的ID.
insert into DISTRIBUTE_ID(createtime) values(NOW()); select LAST_INSERT_ID();SnowFlake 雪花算法(可以⽤,推荐)
雪花算法是Twitter推出的⼀个⽤于⽣成分布式ID的策略。 雪花算法是⼀个算法,基于这个算法可以⽣成ID,⽣成的ID是⼀个long型,那么在Java中⼀个long型是8个字节,算下来是64bit,
如下是使⽤雪花算法⽣成的⼀个ID的⼆进制形式示意:
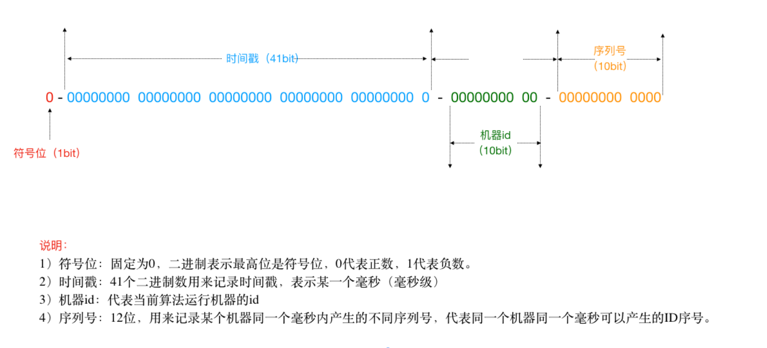
另外,⼀切互联⽹公司也基于上述的⽅案封装了⼀些分布式ID⽣成器,⽐如滴滴的tinyid(基于数据库实现)、百度的uidgenerator(基于SnowFlake)和美团的leaf(基于数据库和SnowFlake)等
借助Redis的Incr命令获取全局唯⼀ID(推荐)
Redis Incr 命令将 key 中储存的数字值增⼀。如果 key 不存在,那么 key 的值会先被初始化为 0 ,然后再执⾏ INCR 操作。