HBASE应用及优化
1. Java客户端
示例代码: client包 https://gitee.com/ixinglan/hbase.git
2. 协处理器
2.1 概念
访问HBase的方式是使用scan或get获取数据,在获取到的数据上进行业务运算。但是在数据量非常大的时候,比如一个有上亿行及十万个列的数据集,再按常用的方式移动获取数据就会遇到性能问题。客户端也需要有强大的计算能力以及足够的内存来处理这么多的数据。
示例代码: client包 https://gitee.com/ixinglan/hbase.git
访问HBase的方式是使用scan或get获取数据,在获取到的数据上进行业务运算。但是在数据量非常大的时候,比如一个有上亿行及十万个列的数据集,再按常用的方式移动获取数据就会遇到性能问题。客户端也需要有强大的计算能力以及足够的内存来处理这么多的数据。

HBase读操作
1)首先从zk找到meta表的region位置,然后读取meta表中的数据,meta表中存储了用户表的region信息
HBase基于Google的BigTable论文而来,是一个分布式海量列式非关系型数据库系统,可以提供超大规模数据集的实时随机读写。
关系型数据库存在空间浪费情况
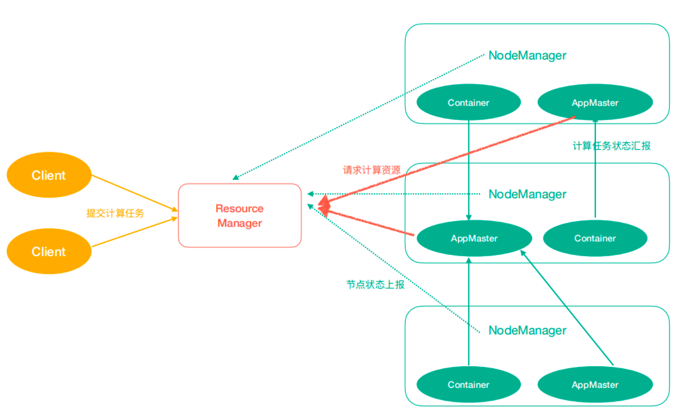
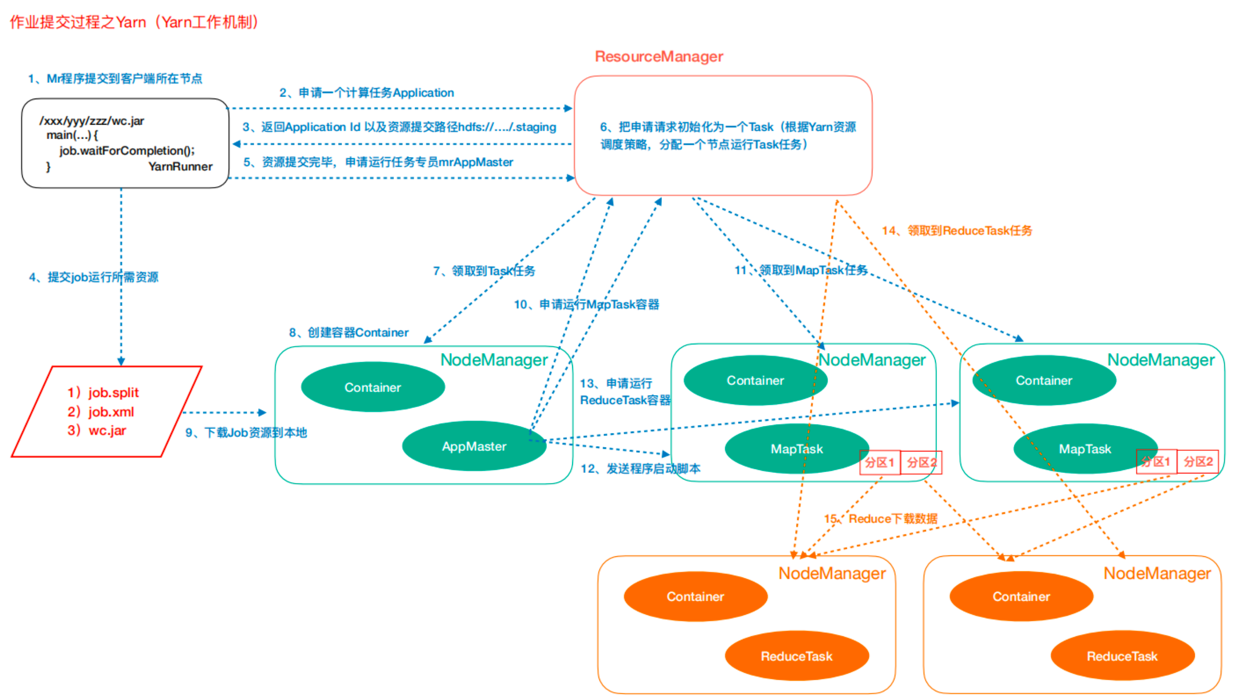
MapReduce思想在生活中处处可见。我们或多或少都曾接触过这种思想。MapReduce的思想核心是分而治之,充分利用了并行处理的优势。